
在为您的组织选择最佳大型语言模型 (LLM)时,需要考虑许多因素。其中一个重要方面是模型的参数数量;通常,较大的模型往往表现更好。您还可以查看性能基准或推理测试,它们提供性能的量化指标,并允许您比较不同的 LLM。
但是,在选择了似乎适合您需求的模型后,您可以通过调整超参数进一步定制它。这些设置可以显著影响 LLM 是否满足或超出您的期望。

什么是 LLM 超参数?为什么它们很重要?
超参数是影响LLM 训练过程的设置。与在训练期间调整的模型参数(或权重)不同,超参数在训练开始前设置并保持不变。它们控制模型如何从训练数据中学习,但不会成为最终模型的一部分。因此,您无法确定训练完成后使用了哪些超参数。
超参数至关重要,因为它们允许您调整模型的行为以更好地满足您的特定需求。您无需从头开始创建自定义模型,而是可以通过超参数调整对现有模型进行微调,以实现所需的性能。
探索不同的 LLM 超参数
1. 模型大小
LLM 的大小(指其神经网络中的层数)是一个主要的超参数。较大的模型通常表现更好,可以处理更复杂的任务,因为它们具有更多的层和权重,使它们能够学习 token 之间的复杂关系。但是,较大的模型训练和运行成本更高,需要更多数据,并且速度可能更慢。它们也更容易过度拟合,即模型在训练数据上表现良好,但在新数据上表现不佳。
较小的模型虽然功能较弱,但可以更有效地完成简单的任务,并且更容易在功能较弱的硬件上部署。它们需要的训练资源较少,并且可以通过量化和微调等技术进一步优化。
2. 周期数
一个 epoch 是完整遍历训练数据集的一次训练。epoch 的数量决定了模型处理整个数据集的频率。更多的 epoch 可以提高模型的理解能力,但如果使用的 epoch 太多,则会导致过度拟合。相反,epoch 太少会导致欠拟合,即模型没有从数据中学到足够的知识。
3.学习率
学习率控制模型在训练过程中响应错误的更新速度。较高的学习率会加快训练速度,但可能会导致不稳定和过度拟合。较低的学习率会增加稳定性并改善泛化能力,但会使训练速度变慢。通常,使用基于时间的衰减、步长衰减或指数衰减等计划随着训练的进展调整学习率是有益的。
4. 批次大小
批次大小是模型一次处理的训练示例数量。较大的批次大小可加快训练速度,但需要更多内存。较小的批次对硬件的要求较低,但可以提高模型从每个数据点学习的彻底程度。
5. 最大输出代币
此超参数也称为最大序列长度,用于设置模型在其输出中可以生成的最大标记数。标记越多,响应越详细、越连贯,但计算和内存需求也会增加。标记越少,这些需求就会减少,但可能会导致响应不完整或连贯性降低。
6. 解码类型
解码是从模型的内部表示生成模型输出的过程。主要有两种类型:贪婪解码,即在每个步骤中选择最可能的标记;抽样解码,即通过从可能的标记子集中进行选择来引入随机性。抽样可以创建更加多样化和富有创意的输出,但会增加无意义响应的风险。
7. Top-k 和 Top-p 采样
使用抽样解码时,top-k 和 top-p 是控制如何选择 token 的附加超参数。Top-k 抽样将模型限制为从概率最高的前 k 个 token 中进行选择。例如,如果将 top-k 设置为 5,则模型将从 5 个最可能的 token 中进行选择。这有助于确保可变性,同时保持对可能选项的关注。
Top-p 采样(或核心采样)根据累积概率动态调整选择池,确保所选标记构成指定的概率质量(例如 90%)。此方法允许模型根据其概率考虑不同数量的标记,从而平衡随机性和连贯性。
当然!让我们来思考一下这句话,“她决定以…开始她的一天”。
现在,让我们看一下结束这个句子的五种可能的方式,每种方式都以不同的标记开头:
读书
慢跑
做早餐
冥想15分钟
在她的日记里写道
我们将为每个初始标记分配一个概率,如下所示:
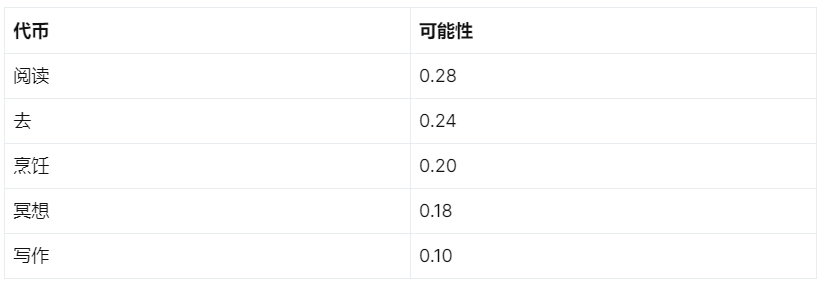
Top-k 采样
如果我们将 top-k 抽样值设置为 2,则抽样子集中只会考虑“reading”和“going”。将其设置为 5 将包含所有选项。
Top-p 抽样
对于 top-p 抽样,如果该值设置为 0.6,则会包括“阅读”和“去”,因为它们的组合概率为 0.52(0.28 + 0.24)。包括“烹饪”将使累积概率为 0.72(0.28 + 0.24 + 0.20),这超过了阈值,因此排除了“烹饪”、“冥想”和“写作”。
如果两个采样值都设置了,则top-k优先,确保所有超出设定阈值的概率都设置为0。
8.温度
温度是一个影响可能输出 token 的范围和模型“创造力”的参数,类似于 top-k 和 top-p 采样值。它用 0.0 到 2.0 之间的十进制数表示。温度为 0.0 会导致贪婪解码,其中始终选择概率最高的 token。相反,温度为 2.0 可以实现最大的创造力。
低温会放大概率之间的差异,使高概率的标记更有可能被选中,从而产生更可预测和可靠的响应。另一方面,高温会导致标记概率收敛,使可能性较小的标记有更好的机会被选中,从而增加随机性和创造性。
9. 停止序列
停止序列提供了一种控制 LLM 响应长度的方法,与最大输出标记参数一起。停止序列是一个或多个字符的特定字符串,遇到该字符串时会停止模型的输出。一个常见的例子是句号(句号)。
或者,您可以使用停止标记限制,即定义输出长度的整数值。例如,将停止标记限制设置为 1 会使生成的输出停止在一个句子处,而将限制设置为 2 会将响应限制为一个段落。这些控制对于管理推理非常有用,尤其是在预算成为问题时。
10. 频率和存在惩罚
频率和存在惩罚是超参数,用于阻止重复并鼓励模型输出的多样性。-2.0 和 2.0 之间的小数表示两种惩罚。
频率惩罚降低了最近使用过的 token 的概率,使其不太可能重复出现。这有助于通过防止重复产生更多样化的输出。存在惩罚适用于至少出现过一次的 token,其工作原理类似,但与 token 使用频率成正比。频率惩罚阻止重复,而存在惩罚鼓励使用更多种类的 token。
什么是 LLM 超参数调整?
LLM 超参数调整涉及在训练过程中调整各种超参数,以找到生成最佳输出的最佳组合。此过程通常涉及大量反复试验,细致地跟踪每个超参数应用并记录结果输出。手动执行此调整非常耗时,因此需要开发自动化方法来简化流程。
自动超参数调整最常见的三种方法是随机搜索、网格搜索和贝叶斯优化:
随机搜索:此方法从指定的值范围内随机选择并评估超参数组合。该方法简单高效,能够探索较大的参数空间。但是,由于其简单性,它可能找不到最佳组合,并且计算成本高昂。
网格搜索:此方法系统地搜索给定范围内所有可能的超参数组合。虽然像随机搜索一样耗费资源,但它可以确保以更系统的方式找到最佳超参数集。
贝叶斯优化:此方法使用概率模型来预测不同超参数的性能,并根据这些预测选择最佳超参数。它比网格搜索更有效,可以用更少的资源处理较大的参数空间。但是,它的设置更复杂,并且在识别最佳超参数集方面可能不如网格搜索可靠。
自动超参数调整的优势
自动超参数调优为机器学习模型开发提供了几个显著的优势。首先,它通过系统地搜索超参数空间节省了时间和精力,从而无需手动反复试验的方法。这可以发现更优化的超参数配置,从而提高模型性能和准确性。此外,自动调优利用了贝叶斯优化、网格搜索和随机搜索等复杂算法,可以更有效地探索超参数格局。
这样可以更快地收敛到最佳设置。此外,自动调整可以轻松集成到现有的机器学习管道中,确保无缝工作流程并通过迭代改进实现持续改进。通过减少对人类专业知识的依赖,它使高级模型调整的访问变得民主化,即使是那些在机器学习方面经验有限的人也可以使用它。
结论
超参数调优通常被视为微调的一个子集,但它是一门值得单独关注的重要学科。通过配置本指南中详细介绍的各种超参数,并观察所选 LLM 的响应情况,您可以增强基础模型的性能,以更好地适应实际应用。
加入捷智算平台
如果您是 AI 研究员、深度学习专家、机器学习专业人士或大型语言模型爱好者,我们希望听到您的声音!加入捷智算平台将让您尽早体验高性价比的算力资源,帮助您实现项目。
不要错过这个激动人心的机会,彻底改变您开发和部署应用程序的方式。立即使用捷智算云平台:https://www.supercomputing.net.cn/











