
部署新的 ML 模型时,很难决定需要哪种 GPU 进行推理。您需要一款能够运行模型的 GPU,但又不想花太多钱购买比您需要的更强大的显卡。本文比较了两种流行的模型推理选择 — NVIDIA 的 A10 和 A100 GPU,并讨论了使用多 GPU 实例处理较大模型的选项。
在为模型推理任务选择 A10 和 A100 时,请考虑延迟、吞吐量和模型大小的要求以及预算。而且您不仅限于单个 GPU。您可以通过在单个实例中组合多个 A100 来运行对于一个 A100 来说太大的模型,并且您可以通过将它们拆分到多个 A10 上来节省一些大型模型推理任务的费用。

本指南将帮助您在为模型推理工作负载选择 GPU 时在推理时间和成本之间做出正确的权衡。
一、关于 Ampere GPU
A10 和 A100 中的“A”表示这些 GPU 是基于 NVIDIA 的Ampere 微架构构建的。Ampere 以物理学家 André-Marie Ampère 的名字命名,是 NVIDIA 推出的一种微架构,用于替代之前的Turing 微架构。Ampere 微架构于 2020 年首次发布,为RTX 3000 系列消费级 GPU提供支持,其中最受瞩目的是 GeForce RTX 3090 Ti,但它在数据中心的影响更大。基于 Ampere 的数据中心 GPU 有六种:
NVIDIA A2
NVIDIA A10
NVIDIA A16
NVIDIA A30
NVIDIA A40
NVIDIA A100(有 40 和 80 GiB 版本)
在这些 GPU 中,A10 和 A100 最常用于模型推理,还有 A10G,这是 A10 的 AWS 特定变体,可互换用于大多数模型推理任务。我们将在本文中比较标准 A10 和 80 GB 的 A100。
二、A10 与 A100:规格
这两款 GPU 都有很长的规格表,但一些关键信息让我们了解 A10 和 A100 在 ML 推理方面的性能差异。
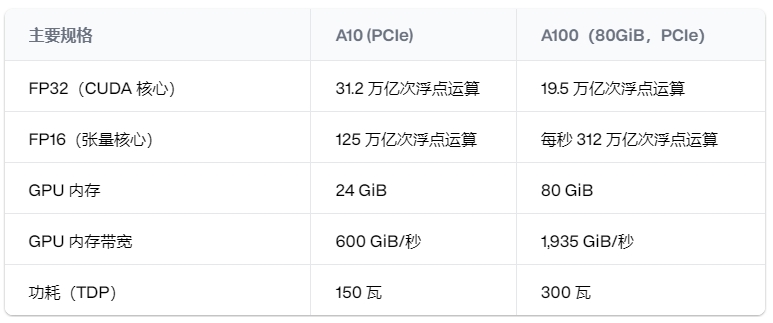
对于机器学习推理来说,最重要的因素是 FP16 Tensor Core 性能,它表明 A100 的性能是 A10 的两倍多,拥有 312 teraFLOP(1 teraFLOP 是每秒一万亿次浮点运算)。A100 还拥有三倍以上的 VRAM,这对于处理大型模型至关重要。
1、核心数量和核心类型
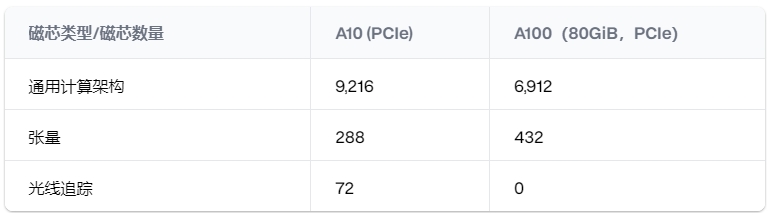
A100 的卓越性能源自其较高的Tensor Core数量。
CUDA 核心是 GPU 中的标准核心。A10 的 CUDA 核心实际上比 A100 多,这与其更高的基本 FP32 性能相对应。但对于 ML 推理而言,Tensor Cores 更为重要。
Ampere 卡采用第三代 Tensor Core。这些核心专门用于矩阵乘法,这是 ML 推理中最耗费计算资源的部分之一。A100 的 Tensor Core 数量比 A10 多 50%,这使其模型推理能力得到极大提升。
光线追踪 (RT) 核心不用于大多数 ML 推理任务。它们更常用于使用 Blender、Unreal Engine 和 Unity 等引擎的面向渲染的工作负载。A100 针对 ML 推理和其他 HPC 任务进行了优化,因此它没有任何 RT 核心。
2、VRAM 和内存类型
VRAM,即视频随机存取存储器,是 GPU 上的内存,可用于存储计算数据。VRAM 通常是模型调用的瓶颈;您需要足够的 VRAM 来加载模型权重并处理推理。
A10 具有 24GiB 的 DDR6 VRAM。同时,A100 有两个版本:40GiB 和 80GiB。两个版本的 A100 都使用 HBM2,这是一种比 DDR6 更快的内存架构。由于采用了 HBM2 架构,A100 比 A10 拥有更大的内存总线和更大的带宽。HBM2 的生产成本更高,因此仅限于这些旗舰 GPU。
Baseten 为 A100 提供 80GiB VRAM,因为这通常是模型推理所需要的。
三、A10 与 A100:性能
规格看起来很棒,但它们如何转化为实际任务?我们在 A10 和 A100 上对Llama 2和Stable Diffusion等流行模型的模型推理进行了基准测试,以了解它们在实际用例中的表现。
这些示例中的所有模型均以浮点 16 (fp16) 运行。这通常称为“半精度”,意味着 GPU 正在对 16 位浮点数进行计算,与以全精度 (浮点 32) 进行计算相比,这可节省大量时间和内存。
1、Llama 2 推理
Llama 2是 Meta 开源的大型语言模型,有三种大小:70 亿、130 亿和 700 亿个参数。模型大小越大,结果越好,但需要更多的 VRAM 来运行模型。
一个好的经验法则是,大型语言模型在 fp16 中运行时,每十亿个参数需要 2 GB 的 VRAM,再加上运行推理和处理输入和输出的一些开销。因此,Llama 2 模型具有以下硬件要求:

A100 GPU 可让您运行更大的模型,对于超过其 80 GB VRAM 容量的模型,您可以在单个实例中使用多个 GPU 来运行该模型。A100 GPU 可让您运行更大的模型,对于超过其 80 GB VRAM 容量的模型,您可以在单个实例中使用多个 GPU 来运行该模型。
2、Stable Diffusion 推理
Stable Diffusion 适用于 A10 和 A100,因为 A10 的 24 GiB VRAM 足以运行模型推理。因此,如果它适用于 A10,为什么还要在更昂贵的 A100 上运行它?
A100 不仅更大,而且速度更快。优化稳定扩散推理后,该模型在 A100 上的运行速度大约是在 A10 上的两倍。
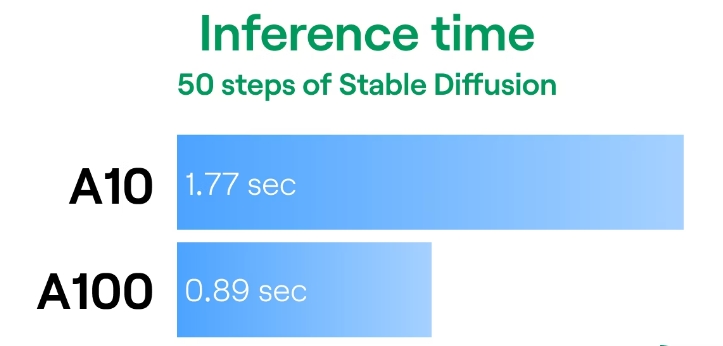
因此,如果必须尽快生成图像,则在 A100 上部署将为您提供单个请求的最快推理时间。
四、A10 与 A100:价格
虽然 A100 比 A10 更大更快,但使用起来也更昂贵。捷智算 的 A100 实例每分钟 0.10240 美元,是最便宜的配备 A10 的实例(每分钟 0.02012 美元)的五倍。
如果更快的推理时间绝对重要,您可以在 A100 上运行较小的模型(如 Stable Diffusion)以获得更快的结果。但成本很快就会增加。因此,如果您主要关心的是吞吐量(单位时间内创建的图像数量,而不是创建每个图像所需的时间),那么您最好水平扩展到多个实例,每个实例都使用 A10。使用 捷智算 ,您可以在每次模型部署时获得自动扩展基础设施,从而使这种水平扩展自动化。
1、计算模型吞吐量
假设您需要 Stable Diffusion 每分钟 1,000 张图像的吞吐量,但生成每张图像需要多少秒并不重要。做出许多现实世界中不存在的简化假设(一致的流量模式、可忽略的网络延迟等),您将从 A10 实例每分钟获得大约 34 张图像,这意味着您将以每分钟约 0.60 美元(每分钟每实例 0.02012 美元乘以 30 个实例)的价格获得所需的吞吐量。
同时,在 A100s 上,您只需要 15 个实例,每分钟就可以生成 67 张图像,但每个实例的成本是其 5 倍,总吞吐量成本约为 1.54 美元/分钟(每个实例每分钟 0.10240 美元乘以 15 个实例),或大约 2.5 倍。

除非生成每张图像的时间非常关键,否则在许多用例中,使用 A10 进行水平扩展可以为您提供比使用 A100 更具成本效益的吞吐量。
管理模型推理的多个副本可能是一个很大的难题,因此 Baseten 提供了自动扩展功能,使吞吐量的扩展变得简单且免维护。
2、多个 A10 与一个 A100
A10 还可以帮助您垂直扩展,创建更大的实例来运行更大的模型。假设您想要运行一个太大而无法在 A10 上容纳的模型,例如Llama-2-chat 13B。除了启动昂贵的 A100 支持的实例之外,您还有另一种选择。
相反,您可以选择在具有多个 A10 的单个实例上运行模型。2 个 A10 合计拥有 48 GiB 的 VRAM,足以满足 130 亿参数模型的需求。具有 2 个 A10 的实例每分钟成本为 0.05672 美元,略高于单个 A100 成本的一半。
当然,在 A100 上推理速度仍然会更快。在一个实例中使用多个 A10 可让您在更大的模型上运行推理,但这不会使推理速度更快。使用多个 A10 而不是 A100 的选项可让您根据用例和预算在速度和成本之间进行权衡。
捷智算 提供多 GPU 实例,最多可配备 8 个 A10 或 8 个 A100。
五、哪种 GPU 适合您?
A100 无疑是一款功能强大的显卡,也是某些 ML 推理任务的唯一选择。但 A10(尤其是在单个实例中具有多个显卡的情况下)为许多工作负载提供了经济高效的替代方案。最终,选择取决于您的需求和预算。
如果 A10 和 A100 都超出了您的使用情况,这里是A10 与较小的 T4 GPU 的比较,与要求不高的推理任务相比,这可以为您节省 A10 的费用。
还有 A10G,这是 A10 的 AWS 专用变体。虽然这些卡具有不同的统计数据,但它们对于大多数模型推理任务而言是可以互换的。
如需估算不同 GPU 的成本,请查看捷智算 的定价页面,并使用我们方便的计算器根据按分钟付费的 GPU 定价估算每月支出。我们随时帮助您找到最适合您的 ML 推理需求的硬件。











