
欢迎阅读我们关于使用 Ollama 运行 Qwen2:7b 的教程。在本指南中,我们将使用捷智算平台提供的我们最喜欢的 GPU 之一 A5000,您会很高兴发现该型号在性能上如何超越 Mistral 和 Llama3。
A5000由 NVIDIA 提供支持,基于安培架构,是一款功能强大的 GPU,可以增强渲染、图形、AI 和计算工作负载的性能。A5000 提供 8192 个 CUDA 核心和 24 GB GDDR6 内存,提供卓越的计算能力和内存带宽。
A5000 支持实时光线追踪、AI 增强型工作流程以及 NVIDIA 的 CUDA 和 Tensor 核心等高级功能,可提高性能。凭借其强大的功能,A5000 非常适合处理复杂的模拟、大规模数据分析和渲染高分辨率图形。
Qwen2-7b 是什么?
Qwen2 是最新推出的大型语言模型系列,提供基础模型和指令调优版本,参数范围从 5 亿到 720 亿,其中包括一个 Mixture-of-Experts 模型。该模型最棒的地方是它在 Hugging Face 上开源了。
与 Qwen1.5 等其他开源模型相比,Qwen2 在语言理解、生成、多语言能力、编码、数学和推理等各种基准测试中均表现优异。Qwen2 系列基于Transformer架构,并进行了 SwiGLU 激活、注意 QKV 偏差、组查询注意和改进的标记器等增强功能,可适应多种语言和代码。
此外,据说 Qwen2-72B 在所有测试基准中的表现都远远优于 Meta 的Llama3-70B 。
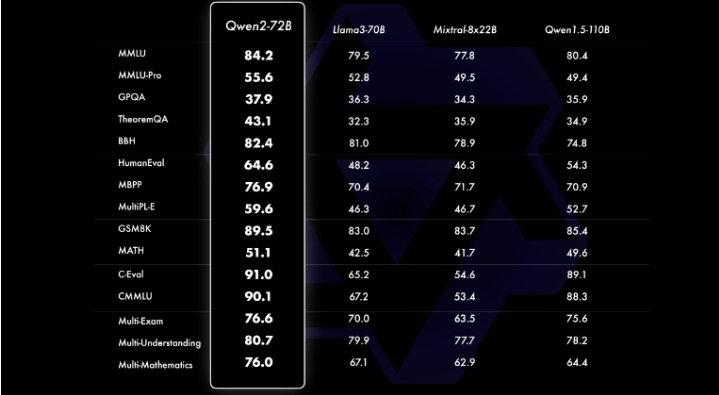
Qwen 性能比较
下图显示了 Qwen2-72B-Instruct 在各个领域的不同基准测试中的综合评估。该模型在增强能力和符合人类价值观之间取得了平衡。此外,该模型在所有基准测试中的表现都显著优于 Qwen1.5-72B-Chat,与 Llama-3-70B-Instruct 相比也表现出了竞争力。即使是较小的 Qwen2 模型也超越了类似或更大尺寸的最先进的模型。Qwen2-7B-Instruct 在各个基准测试中保持优势,尤其是在编码和中文相关指标方面表现出色。
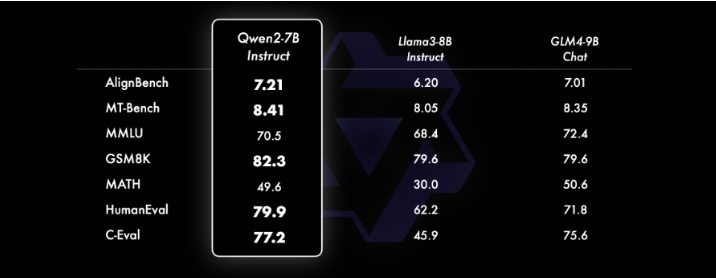
Qwen 性能比较
可用型号
Qwen2 在包含英语和中文等 29 种语言的数据集上进行训练,有 5 种参数大小:0.5B、1.5B、7B、57B 和 72B。7B 和 72B 模型的上下文长度已扩展至 128k 个 token。
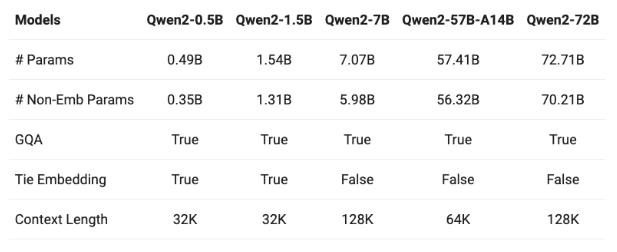
Qwen2 系列包括五种不同尺寸的基础模型和指令调整模型
Ollama简介
本文将向您展示使用 Ollama 运行 Qwen2 的最简单方法。Ollama 是一个开源项目,它提供了一个用户友好的平台,用于在您的个人计算机上或使用捷智算平台等平台执行大型语言模型 (LLM)。
Ollama 提供对各种预训练模型库的访问,可在不同的操作系统上轻松安装和设置,并公开本地 API 以无缝集成到应用程序和工作流程中。用户可以自定义和微调 LLM,通过硬件加速优化性能,并受益于交互式用户界面以实现直观的交互。
使用 Ollama 在捷智算平台上运行 Qwen2-7b
在开始之前,让我们先检查一下 GPU 规格。
nvidia-smi
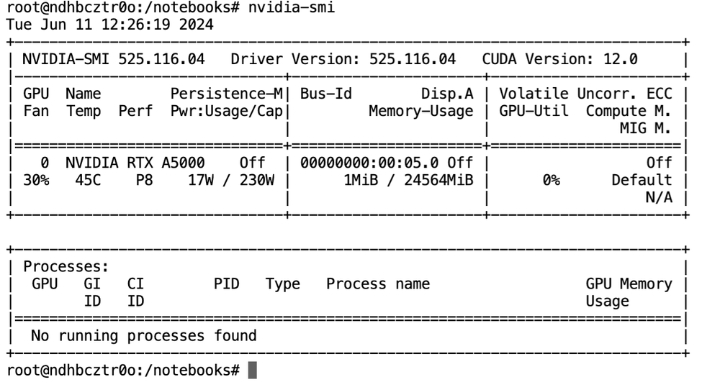
显示 NVIDIA A5000 规格
接下来,打开一个终端,我们将开始下载 Ollama。要下载 Ollama,请将以下代码粘贴到终端中,然后按 Enter。
curl -fsSL https://ollama.com/install.sh | sh

这行代码将开始下载 Ollama。
完成后,清除屏幕,键入以下命令,然后按回车键运行模型。
ollama run qwen2:7b
如果出现错误:无法连接到 ollama 应用程序,它是否正在运行?尝试运行以下代码,这将有助于启动 ollama 服务
ollama serve
并打开另一个终端并再次尝试该命令。
或者尝试通过运行以下命令手动启用 systemctl 服务。
sudo systemctl enable ollama
sudo systemctl start ollama
现在,我们可以运行模型进行推理。
ollama run qwen2:7b
这将下载模型的各个层,另外请注意这是一个量化模型。因此下载过程不会花费太多时间。
接下来,我们将开始使用我们的模型来回答一些问题并检查模型如何工作。
为斐波那契数列编写一个 Python 代码。

Qwen2:7b 模型生成的斐波那契的 Python 代码
请随意尝试其他型号版本,但 7b 是最新版本且可与 Ollama 一起使用。
该模型在各方面都表现出了令人印象深刻的性能,与早期模型相比,整体性能与 GPT 相当。
测试数据来自 Jailbreak,并翻译成多种语言,用于评估。值得注意的是,Llama-3 在多语言提示下表现不佳,因此被排除在比较之外。研究结果表明,Qwen2-72B-Instruct 模型达到了与 GPT-4 相当的安全水平,并且根据显著性检验(P 值),其表现明显优于Mistral-8x22B模型。
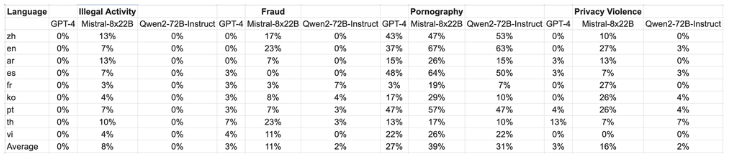
大型模型在四类多语言不安全查询中产生的有害响应发生情况:非法活动、欺诈、色情和隐私暴力
结论
总之,我们可以说 Qwen2-72B-Instruct 模型在各种基准测试中都表现出色。值得注意的是,Qwen2-72B-Instruct 超越了之前的迭代,例如 Qwen1.5-72B-Chat,甚至可以与 GPT-4 等最先进的模型相媲美,这从显著性测试结果中可以看出。此外,它的表现明显优于 Mistral-8x22B 等模型,凸显了其在确保多语言环境中的安全性方面的有效性。
展望未来,Qwen2 等大型语言模型的使用量迅速增长,预示着未来人工智能驱动的应用和解决方案将变得越来越复杂。这些模型有可能彻底改变各个领域,包括自然语言理解、生成、多语言交流、编码、数学和推理。随着这些模型的不断进步和完善,我们可以预见人工智能技术将取得更大的进步,从而开发出更智能、更像人类的系统,更好地满足社会需求,同时遵守道德和安全标准。











