
机器学习 (ML)正在改变各行各业,它能够开发复杂的模型来分析大量数据并做出准确的预测。TensorFlow是一种流行的开源 ML 框架,已成为研究人员和开发人员的强大工具。
TensorFlow 利用图形处理单元 (GPU)的计算能力来加速深度学习模型的训练和推理过程。如前所述,GPU 擅长并行处理,使其成为处理 ML 任务所需的密集计算的理想选择。领先的 GPU 制造商 NVIDIA 提供了一系列专为机器学习工作负载设计的高性能选项。
在本文中,我们将比较 NVIDIA A4000 和 A5000 GPU。两者都是NVIDIA 安培架构的一部分,与前几代相比,该架构提供了显着的性能改进。我们的比较将评估它们在运行 TensorFlow 时的性能,并深入了解哪种 GPU 在各种机器学习任务中表现更好。
为什么使用 GPU 来完成机器学习任务?
我们已经广泛讨论了 GPU 如何通过并行处理能力彻底改变机器学习和深度学习。凭借数千个核心,GPU 可以满足大规模机器学习算法的计算需求,从而实现更快的训练、更快的模型开发以及高效处理复杂计算。
GPU 专为处理机器学习中常见的矩阵乘法和浮点计算而设计,非常适合数据密集型任务。通过利用 GPU,研究人员和开发人员可以管理海量数据集并加速训练和推理过程,最终推动机器学习领域的发展。
什么是 TensorFlow?
TensorFlow 是一个广泛使用的开源机器学习框架,受到研究人员、开发人员和行业专业人士的青睐。它为构建、训练和部署各种机器学习模型(包括神经网络)提供了一个全面的生态系统。
TensorFlow 的底层实现是使用多维数组(称为张量)来定义和操作数学运算。这些张量在计算图中移动,其中节点表示运算,边表示数据依赖关系。这种基于图的方法可以实现高效的并行计算,使 TensorFlow 成为大规模数据处理和复杂数学运算的理想选择。
TensorFlow 具有高级 API,可简化机器学习模型的创建和训练。用户可以从各种预构建的层、激活函数和优化算法中进行选择,也可以创建自定义组件以满足其特定需求。此外,TensorFlow 支持多种数据格式,并与其他流行库(如NumPy和Pandas)无缝集成,从而方便将其纳入现有工作流程。
TensorFlow 的一个显著优势是它能够利用 GPU 来加速机器学习任务。它与 NVIDIA GPU 的兼容性尤其值得注意。NVIDIA 提供了 GPU 加速库,如计算统一设备架构 (CUDA)和CUDA 深度神经网络 (cuDNN),TensorFlow 使用这些库在 NVIDIA GPU 上高效执行计算。
CUDA是一个并行计算平台和 API,可让开发人员充分利用 NVIDIA GPU。得益于其大规模并行架构,TensorFlow 使用 CUDA 将计算密集型操作卸载到 GPU。这种 GPU 加速大大加快了训练和推理过程,从而加快了模型开发和部署速度。
另一方面,cuDNN是一个专为深度神经网络设计的 GPU 加速库。它提供了卷积和池化等基本操作的高度优化实现,使 TensorFlow 在 NVIDIA GPU 上运行时能够实现更高的性能。
通过 CUDA 和 cuDNN 利用 GPU,TensorFlow 可帮助机器学习从业者训练更复杂的模型、处理更大的数据集并更快地获得结果。此功能确保 TensorFlow 始终处于先进机器学习研究和开发的前沿。
NVIDIA A4000 和 A5000 的规格
NVIDIA A4000 和 A5000 GPU 属于 Ampere 架构的一部分,与前几代产品相比,性能显著提升。这些 GPU 专为满足机器学习任务(包括使用 TensorFlow 的任务)的苛刻要求而量身定制。
以下是与机器学习相关的关键技术规格:
NVIDIA A4000:
内存带宽:高达 512 GB/s
CUDA 核心数: 6144
张量核心: 192
最大功耗: 140W
内存大小: 16GB GDDR6
NVIDIA A5000:
内存带宽:高达 768 GB/s
CUDA 核心数: 8192
张量核心: 256
最大功耗: 230W
内存大小: 24GB GDDR6
两款 GPU 都具有大量内存带宽,这对于高效地将数据传送到计算核心至关重要。A5000 拥有更多 CUDA 核心,可以同时管理更多并行任务,从而可能缩短训练和推理时间。此外,两款 GPU 中的张量核心都有助于加速混合精度运算,这在深度学习中很常用。
TensorFlow 中 A4000 与 A5000 的比较分析
与 NVIDIA A4000 相比,A5000 提供更多 CUDA 核心、更大的内存容量和更高的内存带宽。这些增强的规格使 A5000 成为更密集的计算任务的理想选择,特别是在 AI 研究、数据科学和高级设计可视化领域。以下是主要区别:
架构和制造工艺:这两款 GPU 均基于 Ampere 架构,这增强了它们有效处理并行处理和复杂图形和 AI 计算的能力。
性能核心: A5000 具有更多 CUDA 核心(8,192 个 vs. 6,144 个),这对于并行处理和加速计算任务至关重要。核心数量的增加可以带来更好的性能。
内存:与 A4000 的 16 GB 相比,A5000 提供更大的 24 GB GDDR6 内存容量。此外,A5000 的内存带宽更高,为 768 GB/s,而 A4000 为 448 GB/s。这使得 A5000 能够管理更大的数据集并实现更快的数据传输速率。
功耗: A5000 的功耗率为 230 W,高于 A4000 的 140 W。这种增加的功耗可能需要更强大的冷却解决方案,对于系统构建者来说,这是一个重要的考虑因素。
目标应用:虽然这两种 GPU 都是为专业环境中的高性能计算而设计的,但 A5000 拥有更大的 CUDA 核心数量、更大的内存容量和更高的内存带宽,使其更适合执行要求苛刻的任务和处理更大的数据集。
基准和性能指标
在比较用于 TensorFlow 任务的 GPU 时,几个性能指标至关重要:
处理速度: GPU 执行计算的速度对于减少训练和推理时间至关重要。具有更多 CUDA 核心和更高时钟速度的 GPU 通常可提供更快的处理速度。
内存利用率: GPU 的内存带宽和容量对于高效处理大型数据集至关重要。更高的内存带宽可以加快与 GPU 之间的数据传输速度,而更大的内存容量则可以处理更广泛的模型和数据集。
电源效率:功耗是一个重要因素,特别是对于大型机器学习项目而言。提供高性能同时最大限度降低功耗的 GPU 可以节省成本并带来环境效益。
这些指标共同影响 TensorFlow 任务的整体性能和有效性,包括训练神经网络、数据处理速度和模型准确性。
以下是 A4000 和 A5000 的一些关键性能基准:
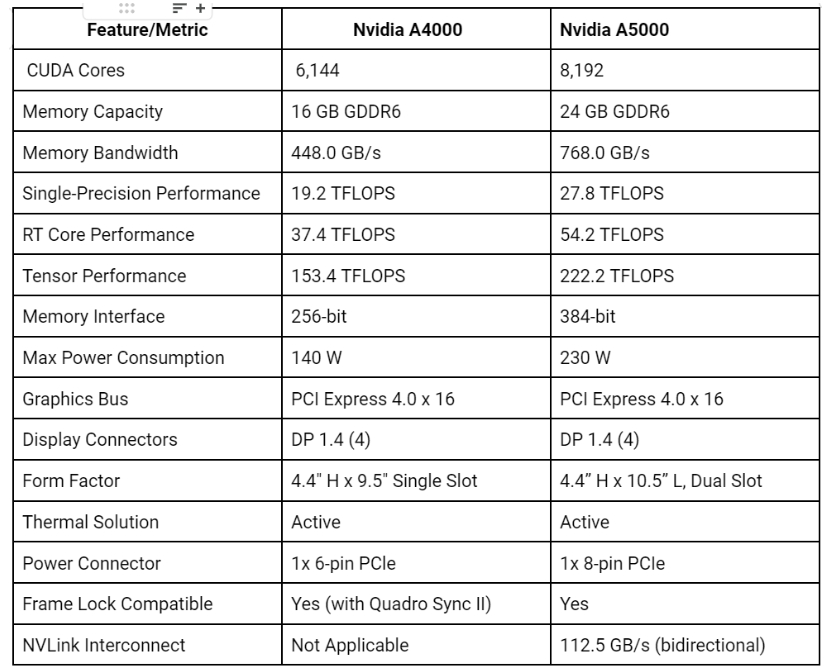
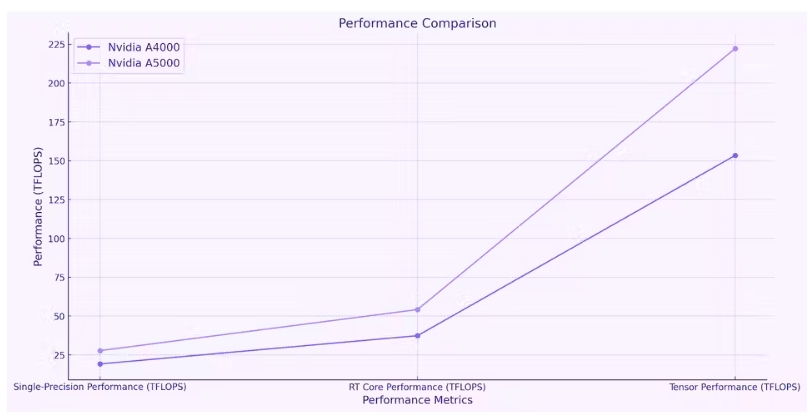
NVIDIA A4000 和 A5000 GPU 为 TensorFlow 任务提供了强大的计算能力,其中 A5000 在大多数指标上的表现通常优于 A4000。这两款 GPU 都具有大量 CUDA 核心,这些核心是并行处理器,可大大加速计算任务。不过,A5000 的数量为 8192,而 A4000 的数量为 6144。
在内存容量方面,A5000 的 24 GB GDDR6 超过了 A4000 的 16 GB,使其能够在 GPU 内存中容纳更多数据,这对于大规模 TensorFlow 任务尤其有利。
内存带宽(衡量从 GPU 内存读取或写入数据的速度)在 A5000(768 GB/s)中也高于 A4000(448 GB/s)。就单精度性能(衡量 GPU 执行浮点计算的速度)而言,A5000 的表现优于 A4000,提供 27.8 TFLOPS,而 A4000 为 19.2 TFLOPS。
与 A4000(37.4 TFLOPS)相比,A5000 还具有卓越的 RT Core 性能(54.2 TFLOPS),表明光线追踪能力更佳。
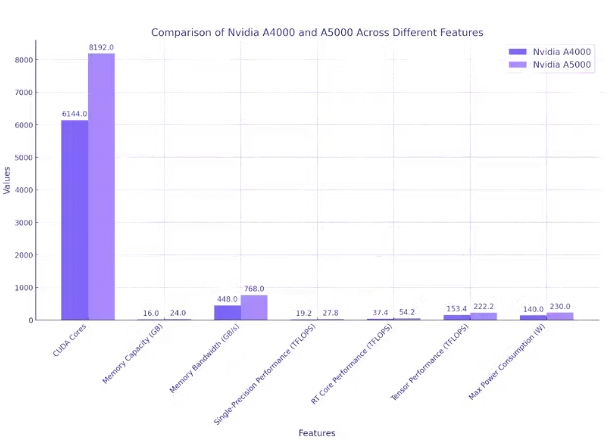
张量性能(衡量张量运算效率)是 A5000 的另一个出色领域。它提供 222.2 TFLOPS,明显高于 A4000 的 153.4 TFLOPS。A5000 确实消耗更多电量,最大消耗为 230 W,而 A4000 为 140 W。
两款 GPU 均配备四个 DP 1.4 显示连接器,但 A5000 的外形尺寸更大,需要更强大的电源连接器(1 个 8 针 PCIe,而 A4000 为 1 个 6 针 PCIe)。虽然两款 GPU 都兼容帧锁,但只有 A5000 支持 NVLink Interconnect,提供 112.5 GB/s(双向)的速度。
总体而言,这两款 GPU 都非常适合 TensorFlow 任务,但 A5000 在多个指标上通常都表现优异。然而,这种增强的性能是以更高的功耗为代价的。
关于 A4000 和 A5000 用于机器学习的最终想法
由于规格不同,NVIDIA A4000 和 A5000 GPU 的 TensorFlow 性能也有所不同。A5000 拥有更多 CUDA 核心和更大内存,在需要大量并行处理和大数据集处理的任务(例如训练复杂的深度学习模型)中表现出色。相比之下,由于功耗较低,A4000 对于要求不高的任务效率更高。对于大型数据集,A5000 的更大内存和更高带宽可以缩短计算时间,而这两种 GPU 都可以为较小的数据集提供令人满意的性能。
因此,两者之间的选择取决于任务的具体要求。
为 TensorFlow 项目选择合适的 GPU 需要考虑性能、成本效益、能耗、使用寿命和可扩展性。通过评估这些因素并了解 GPU 技术和 TensorFlow 的进展,数据科学家和 ML 工程师可以做出明智的决策,以优化他们的机器学习工作流程并实现他们的项目目标。











