
NVIDIA 的 GH200 Grace Hopper 超级芯片平台显著推动了加速计算和生成式 AI 的发展。该平台将全球最强大的 GPU 与适应性最强的 CPU 结合在一起。NVIDIA GH200 的可扩展设计可以管理复杂的生成式 AI 任务,包括大型语言模型 (LLM)、推荐系统、矢量数据库、图神经网络 (GNN)等。那么NVIDIA GH200 究竟是什么呢?下面一起了解一下关于 NVIDIA GH200 你需要知道的一切。
NVIDIA 创始人兼首席执行官黄仁勋表示:“数据中心需要专门的加速计算平台来满足对生成式 AI 日益增长的需求。” GH200 的设计正是满足了这一需求。黄仁勋指出:“该 GPU 提供了出色的内存技术和带宽,可提高吞吐量,允许 GPU 连接和聚合性能而不会受到影响,并且具有可轻松跨数据中心部署的服务器设计。”
革命性的内存和带宽
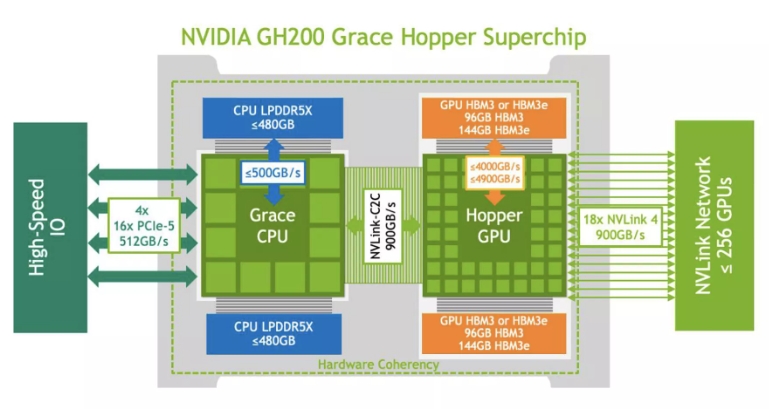
GH200 的架构树立了新的高性能计算 (HPC) 标准。它将先进的 Hopper GPU 和灵活的 Grace CPU 集成到单个超级芯片中,并通过高速、内存一致的NVIDIA NVLink Chip-2-Chip (C2C) 互连进行连接。
GH200 Grace Hopper 超级芯片的核心是 NVLink-C2C 互连,可提供 900GB/s 的双向 CPU-GPU 带宽,是传统加速系统中 PCIe Gen5 连接性能的七倍。此外,互连功耗降低了五倍以上。
NVLink-C2C 允许应用程序直接利用 Grace CPU 的高带宽内存来超额使用 GPU 的内存。GH200 提供高达 480GB 的 LPDDR5X CPU 内存,当与 96GB HBM3 或 144GB HBM3e 结合使用时,Hopper GPU 可以访问高达 624GB 的高速内存。
主要特点和初始基准
NVIDIA Grace CPU 的主要属性包括:
与标准 x86-64 平台相比,每瓦性能提高一倍
72 个 Neoverse V2 Armv9 内核,配备高达 480GB 的服务器级 LPDDR5X 内存,具有纠错码 (ECC)
与八通道 DDR5 设计相比,带宽增加高达 53%,而每 GB 每秒的功耗仅为八分之一
基于全新 Hopper GPU 架构构建的 H100 Tensor Core GPU 具有多项创新功能:
通过全新第四代 Tensor Core 实现极快的矩阵计算,支持更广泛的 AI 和 HPC 任务
与上一代 NVIDIA A100 相比,全新 Transformer Engine 可将 AI 训练速度提高 9 倍,将 AI 推理速度提高 30 倍
通过安全的多实例 GPU (MIG) 分区,将 GPU 划分为独立且大小合适的实例,从而提高较小工作负载的服务质量
总结来说,GH200 性能强大,但由于发布时间不长,综合基准测试数据仍然有限。不过,让我们回顾一下一些初步结果。
初始基准:GH200 与其竞争对手的比较
经过测试的 GH200 系统具有 72 个内核、一块 Quanta S74G 主板、480GB RAM 和 960GB + 1920GB SAMSUNG SSD 驱动器。这些初步基准测试强调了 CPU 性能,但没有功耗数据,但它们揭示了值得注意的结果。
GH200 Grace CPU 在标准HPCG 内存带宽基准测试中实现了 41.7 GFLOPS 。
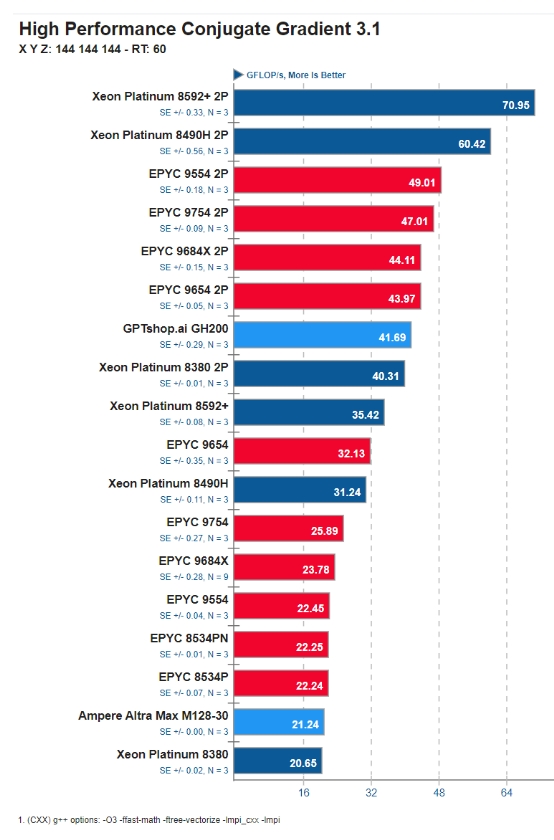
NVIDIA GH200 运行 HPCG 基准测试的结果
另一个重要的结果来自NWChem 基准测试,GH200 以 1403.5 秒的成绩获得第二名。
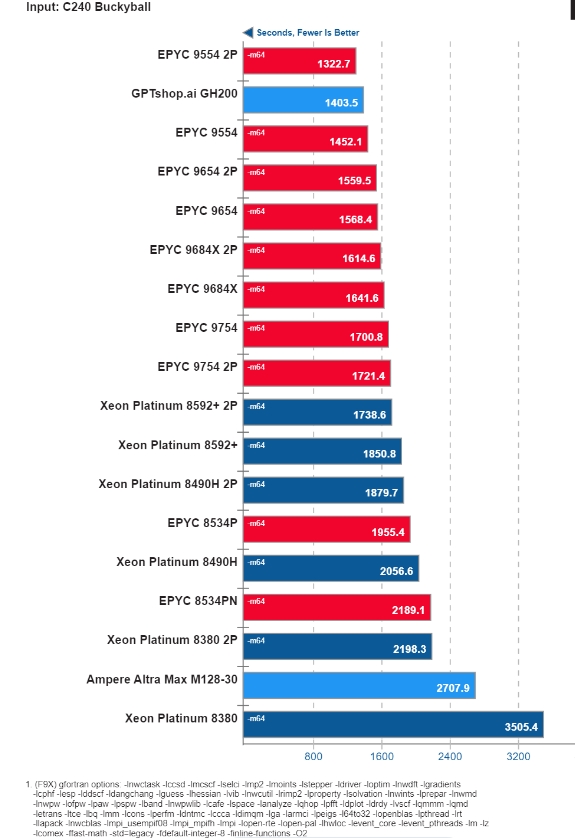
NVIDIA GH200 运行 NWChem 基准测试的结果
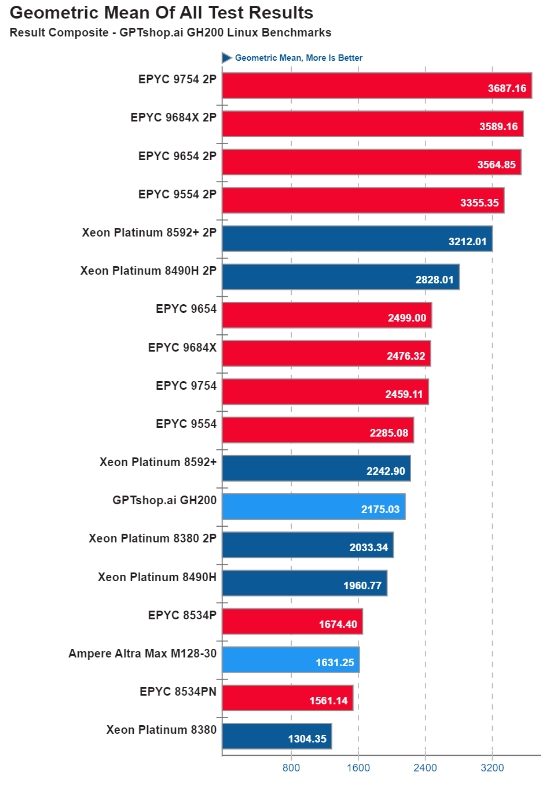
GH200 Grace CPU 的整体性能令人称赞,在所有基准测试中都取得了可观的几何平均值。
研究员 Simon Butcher进行了一系列 GPU 基准测试,比较了NVIDIA 发布的PyTorch ResNet50 训练方案的性能。使用 150GB ImageNet 2012 数据集,训练运行了 90 个 epoch,大约一个小时。GH200 在这些测试中表现出色。
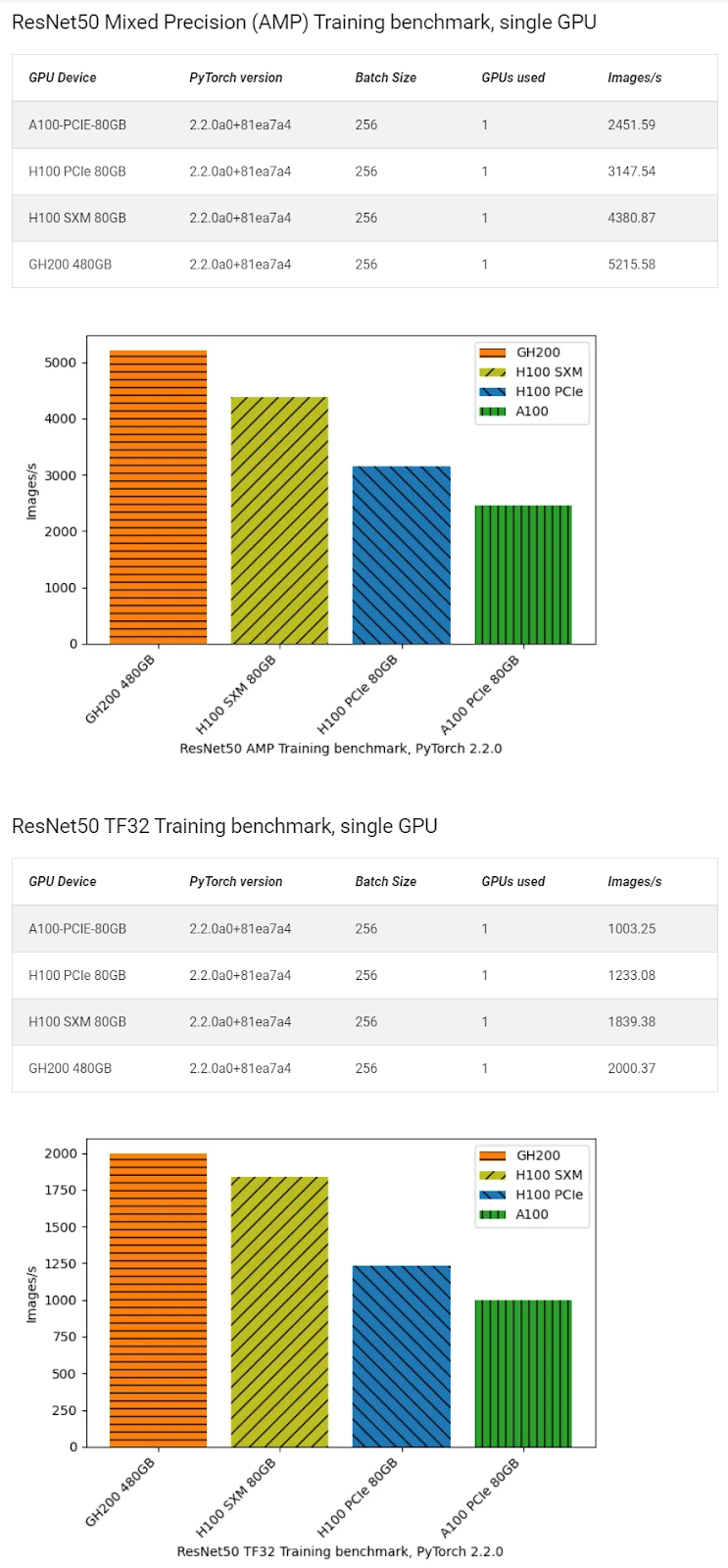
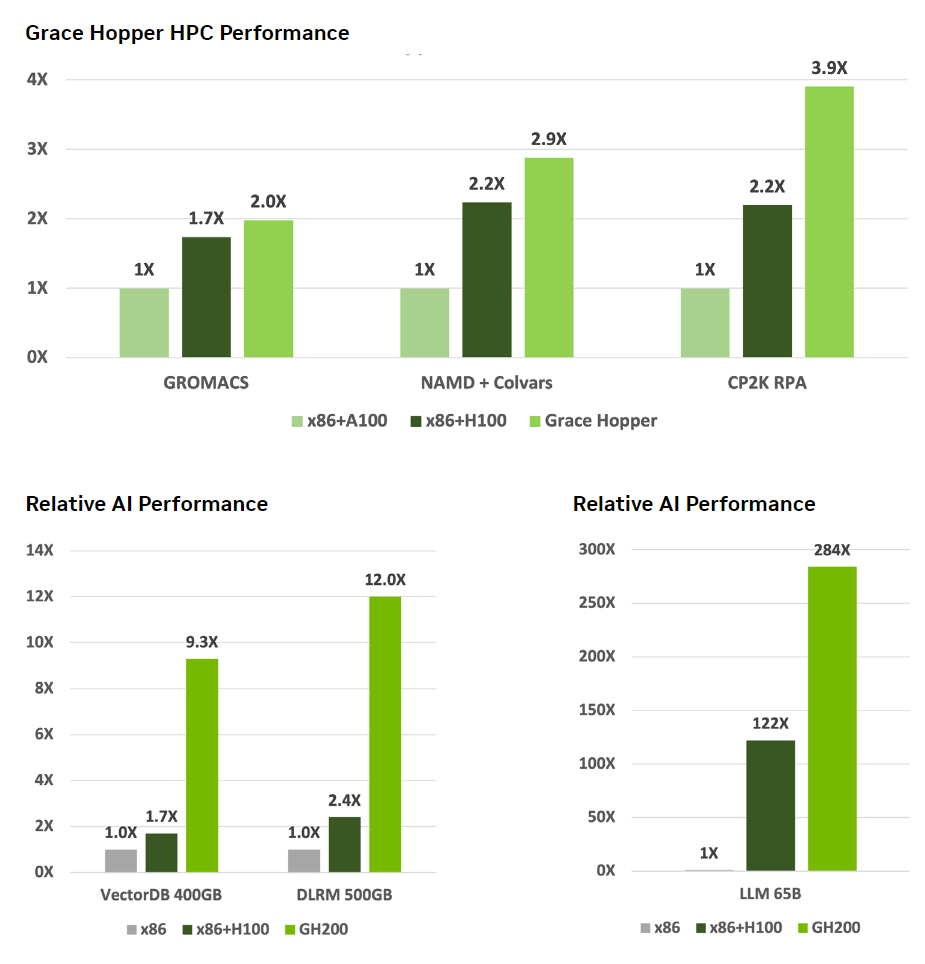
NVIDIA 还发布了一些可能引起人们兴趣的性能比较。
结论
NVIDIA GH200 Grace Hopper 超级芯片提供处理 TB 级数据的大规模 AI 和 HPC 应用程序所需的性能。无论您是科学家、工程师还是管理大型数据中心,这款超级芯片都能满足需求。
展望未来,NVIDIA 推出了GH200 的继任者:Grace Blackwell B200,即下一代数据中心和 AI GPU。
随着对 GPU 资源的需求不断激增,尤其是对于人工智能和机器学习应用的需求,确保这些资源的安全性和易于访问变得至关重要。
捷智算平台的去中心化架构旨在使全球尚未开发的 GPU 资源的访问变得民主化,并高度强调安全性和用户便利性。让我们来揭秘捷智算平台如何保护您的 GPU 资源和数据,并确保去中心化计算的未来既高效又安全。











