
数据中心 GPU 在未来几年仍将保持重要地位 - 如今仍有 K80 在运行生产工作负载 - 而随着 NVIDIA 强调每个新系列 GPU 的优势,用于推销这些显卡的术语也会随着时间而改变。
那么,有哪些可靠的指标可用于比较不同架构和层级的 GPU,以决定哪一种是运行工作负载最具成本效益的方式?我们将考虑核心数量、FLOPS、VRAM 和 TDP。本指南可帮助您根据实际需求对显卡进行公平比较。
一、核心数量
您分析的显卡可能有几种不同类型的核心:
CUDA 核心:最通用的核心,适用于各种计算任务。
张量核:针对某些机器学习计算进行了优化。
光线追踪 (RT) 核心:对于游戏而言比大多数 ML 更为重要,这些核心专门用于模拟光的行为。
原始核心数量是一个很好的信号,但并不是全部。不同的显卡有不同类型的核心——有些有更多张量核心,有些有更多 CUDA 核心——而新架构的显卡也可能有某些类型核心的新一代。正确的比较需要一个更标准化的指标:FLOPS。
二、FLOPS
FLOPS 代表每秒浮点运算次数,是 GPU 性能的关键衡量标准。
不过,还有一个复杂的因素。GPU 性能的测量精度各不相同。精度是指计算中每个数字的大小,从 8 位整数到 64 位双精度浮点值。

数字格式和相应的位的使用
更高精度的数字格式的计算需要更多的处理能力。但这正是 Tensor 核心发挥作用的地方。Tensor 核心可以进行混合精度计算,它们在大多数计算中使用较低的精度,然后以更高的精度验证结果。比较相同精度上相同核心类型的 FLOPS,以便在 GPU 之间进行适当的同类比较。
例如,在最高精度(FP64)下,NVIDIA 的顶级 A100 GPU 在标准 CUDA 核心上达到 9.7 teraFLOPS,但其 Tensor 核心在相同精度下将该性能提高了一倍,达到 19.7 teraFLOPS。
精度越低,FLOPS 数量越高。例如,以下是 A10 和 A100 GPU 在不同精度下的计算能力比较。
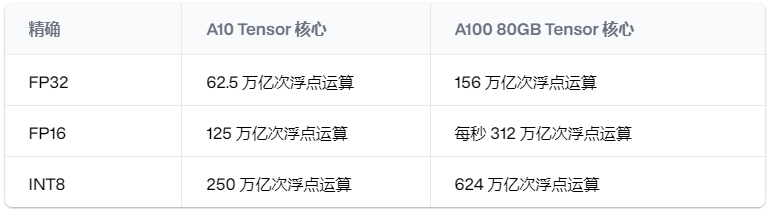
不同精度下 A10 和 A100 的每秒操作数比较
三、VRAM
VRAM(视频随机存取存储器)是显卡的板载内存。VRAM 之于 GPU 相当于 RAM 之于 CPU。它存储模型权重等数据,以便在模型推理等计算过程中快速访问。
模型服务最重要的因素是 GPU 拥有的 VRAM 数量。为了快速调用,模型权重必须存储在 VRAM 中,因此 VRAM 容量限制了模型大小。
并非所有 VRAM 都等效。还有三个因素需要考虑:
总线大小衡量一次可传输到 VRAM 和从 VRAM 传输的数据量。总线越大,模型权重加载速度越快。
时钟速度衡量 VRAM 处理数据的速度,时钟速度越高,内存读写速度越快。
GDDR和HBM是两种不同类型的 VRAM。HBM(高带宽内存)通常提供更高的带宽和更低的功耗,但制造成本比 GDDR(图形双倍数据速率)内存更高。最近的 100 层卡(如 A100 和 H100)使用 HBM。
更糟糕的是,并非所有同级别的 GPU 都具有相同数量的 VRAM。例如,A100 有 40GB 和 80GB 版本。因此,在配置 GPU 之前,请确保它具有足够数量的 VRAM 来运行您的模型。
四、TDP
TDP 代表热设计功耗,指的是 GPU 在运行时设计的最大功耗(瓦特数)。高端显卡的 TDP 通常比低端显卡高,但这并不是完美的对应关系。
数据中心根据多种因素来为 GPU 计算时间定价,但显卡的 TDP 是其中之一。电力需要花钱,而且还会产生热量,而消除热量则需要花费更多钱。因此,TDP 较高的显卡的运营成本也较高,这将影响您作为最终用户为计算时间支付的价格。
总结:选择你的 GPU
过去十年,数据中心 GPU 的发布已经达到二十多种,为了避免众多GPU 之间的选择,您可以直接找捷易科技进行定制化购买服务。











