
NVIDIA 拥有数十种 GPU,可用于处理不同大小的 ML 模型。但要了解这些不同显卡的性能和成本,更不用说记住它们的名称,却是一项挑战。每个 GPU 的名称(一个字母数字标识符)都传达了有关其架构和规格的信息。
每个人都想要功能强大、经济高效的硬件来运行生成式 AI 工作负载和 ML 模型推理。但选择数据中心 GPU 并不像走进 Apple 商店挑选一台新笔记本电脑那么简单,因为那里只有少数几个选项和明确的升级路径。这更像是买车,您的预算和用例会指导您在具有不同功能、价格和可用性的一系列型号和车型年份中做出决定。
本文首先会引导您解读 NVIDIA 数据中心 GPU 的命名方案,以识别显卡的架构和层级。然后,本文将提供清晰直接地比较不同 GPU 的方法,以及用于模型训练、微调和服务的几款流行显卡的关键规格表。
数据中心 GPU 可以有相当神秘的名称:K80、T4、A100、L40。但这些不仅仅是字母和数字的随机集合。它们编码了有关 GPU 规格和性能的重要信息。
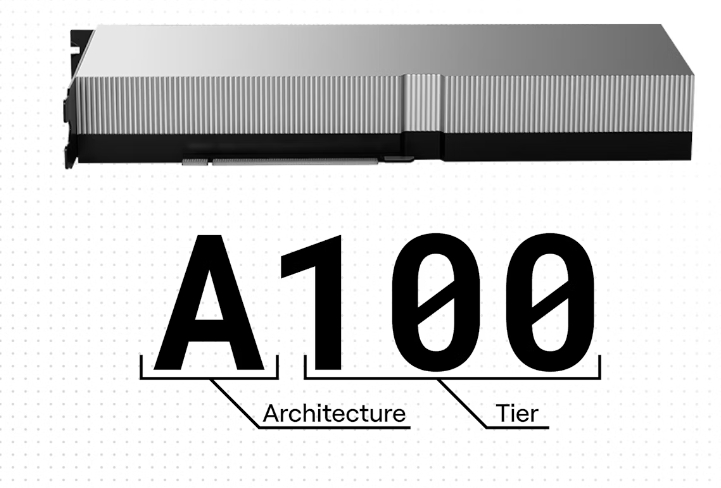
一、字母:显卡架构
GPU 名称中的字母代表该 GPU 的架构。每隔几年,NVIDIA 就会为消费级和数据中心产品的 GPU 发布一种新的微架构。新的微架构通过更新的指令集提高了性能和能效,并且通常利用更小的工艺节点将更多的晶体管封装到每个芯片上。每个新的微架构都意味着更快、更优化的 GPU。
在 GPU 的名称中,字母是架构名称的首字母。例如,A 代表 Ampere,L 代表 Lovelace。NVIDIA GPU 架构以著名科学家的名字命名。

二、卡层数
对于每种架构,NVIDIA 都会制造几种具有不同价格、性能和功耗目标的 GPU。数字越大,GPU 的功能越强大,价格也越昂贵。
不同级别的 GPU 针对不同的计算工作负载进行了优化。最近几代的 GPU 级别包括:
4:一代中最小的 GPU,4 层卡能耗低,最适合经济高效地调用中等大小的模型。
10:针对AI推理优化的中端GPU。
40:最适合虚拟工作站、图形和渲染的高端 GPU。
100:这一代 GPU 中规模最大、价格最昂贵、性能最强。它拥有最高的核心数和最大 VRAM,专为大型模型推理以及新模型的训练和微调而设计。
三、示例比较
有了这两个因素,我们可以使用 GPU 名称中的字母和数字组合来推断有关卡的一些事实。
例如:T4 和 L4 有什么区别?
L4 是 T4 的下一代替代品。L4 使用 Lovelace 架构,于 2023 年发布,而 T4 使用 Turing 架构,于 2018 年发布。这两款显卡属于同一层级——它们使用的功率相似,设计用于相似的用例——但较新的 L4 拥有更强大的内核和 24 GB 的 VRAM,而 T4 只有 16 GB。
例如:A10 和 A100 有什么区别?
A100 是 A10 的更大、更强大、更昂贵的版本。两款显卡具有相同的架构,但 A100 拥有更多内核和 VRAM,功耗更高,因此它可以运行更大的模型,并且运行速度更快。
例如:如何比较 K80 和 T4?
任何两张不同架构和不同级别的显卡之间的比较都很复杂。K80 采用已有十年历史的 Kepler 架构,而 T4 采用更现代的 Turing 架构。因此,对于许多 ML 任务而言,T4 每分钟的运行成本更低(因为功耗更低),同时由于其核心更强大,运行速度也比 K80 快得多。











