
随着构建生成式 AI 变得越来越主流,有两种 NVIDIA GPU 型号已成为每个 AI 构建者基础设施愿望清单的首选——H100 和 A100。H100 于 2022 年发布,是目前市场上功能最强大的显卡。A100 可能较旧,但仍然很熟悉、可靠且功能强大,足以处理要求苛刻的 AI 工作负载。
关于单个 GPU 规格的信息很多,但我们不断听到客户说他们仍然不确定哪种 GPU 最适合他们的工作量和预算。H100 表面上看起来更贵,但它们能通过更快地执行任务来节省更多钱吗?
A100 和 H100 具有相同的内存大小,那么它们最大的区别在哪里?通过这篇文章,我们希望帮助您了解当前用于 ML 训练和推理的主要 GPU(H100 与 A100)之间需要注意的主要区别。
技术概述
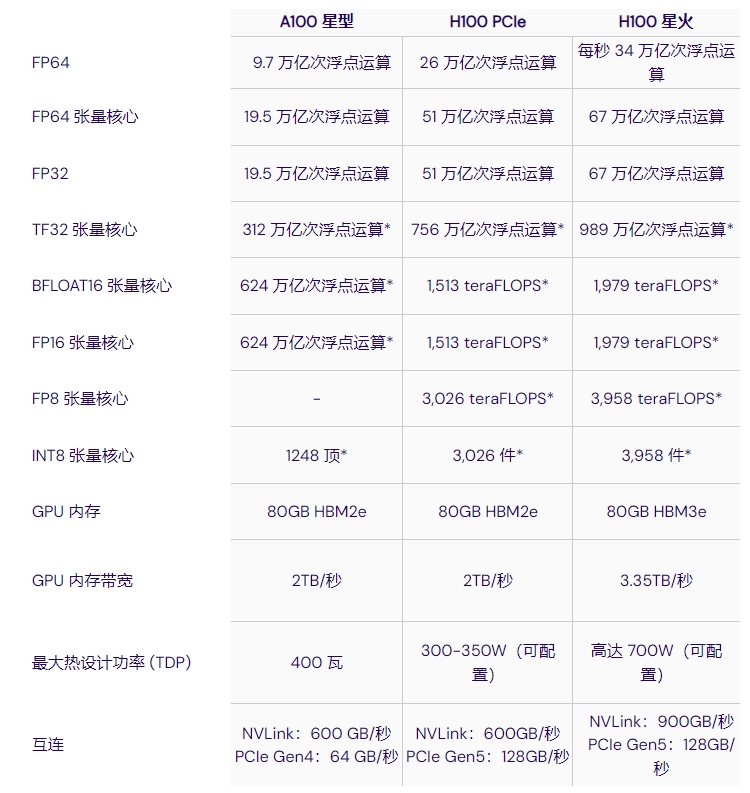
表 1 - NVIDIA A100 与 H100 的技术规格
据 NVIDIA 介绍,H100 的推理性能最高可提高 30 倍,训练性能最高可提高 9 倍。这得益于更高的 GPU 内存带宽、升级的 NVLink(带宽高达 900 GB/s)和更高的计算性能,H100 的每秒浮点运算次数 (FLOPS) 比 A100 高出 3 倍以上。
Tensor Cores:与 A100 相比,H100 上的新型第四代 Tensor Cores 芯片间速度最高可提高 6 倍,包括每个流多处理器 (SM) 加速(2 倍矩阵乘法-累积)、额外的 SM 数量和更高的 H100 时钟频率。值得一提的是,H100 Tensor Cores 支持 8 位浮动 FP8 输入,可大幅提高该精度的速度。
内存: H100 SXM 具有 HBM3 内存,与 A100 相比,带宽增加了近 2 倍。H100 SXM5 GPU 是世界上第一款具有 HBM3 内存的 GPU,可提供 3+ TB/秒的内存带宽。A100 和 H100 都具有高达 80GB 的 GPU 内存。
NVLink: H100 SXM 中的第四代 NVIDIA NVLink 比上一代 NVLink 的带宽增加了 50%,多 GPU IO 的总带宽为 900 GB/秒,运行带宽是 PCIe Gen 5 的 7 倍。
性能基准
在 H100 发布时,NVIDIA 声称 H100 可以“与上一代 A100 相比,在大型语言模型上提供高达 9 倍的 AI 训练速度和高达 30 倍的 AI 推理速度”。根据他们自己发布的数据和测试,情况确实如此。然而,测试模型的选择和测试参数(即大小和批次)对 H100 更有利,因此我们需要谨慎对待这些数据。
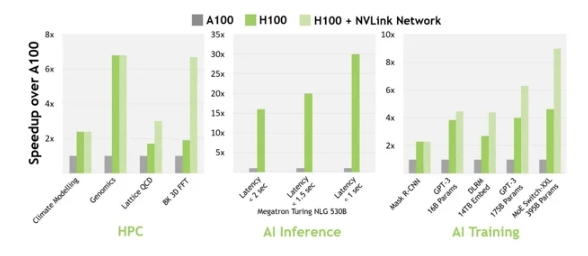
NVIDIA基准测试 - NVIDIA H100 与 A100
其他来源也进行了基准测试,结果表明 H100 的训练速度比 A100 快 3 倍左右。例如,MosaicML 在语言模型上进行了一系列具有不同参数数量的测试,发现以下情况:
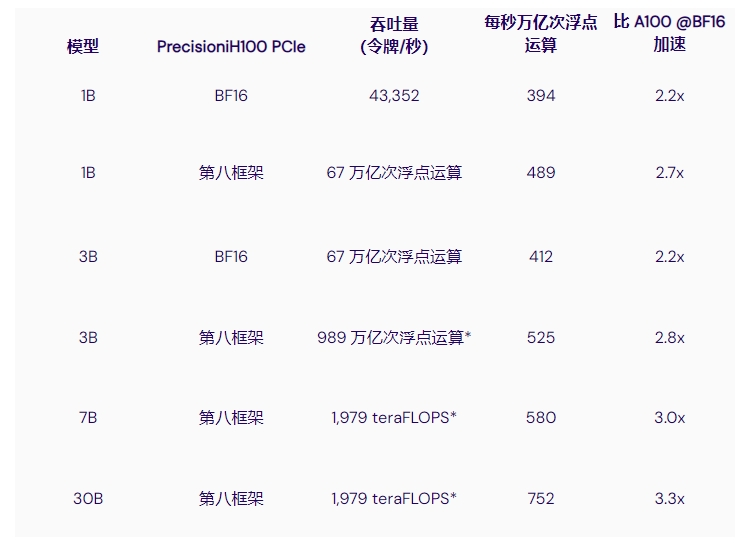
MosaicML基准测试 - NVIDIA H100 与 A100
LambaLabs 尝试使用 FlashAttention2 训练大型语言模型(具有 175B 个参数的类 GPT3 模型)对两种 GPU 进行基准测试时,获得的改进较少。在这种情况下,H100 的性能比 A100 高出约 2.1 倍。
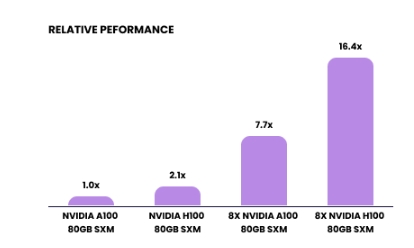
175B LLM 上的 FlashAttention2 培训
虽然这些基准测试提供了有价值的性能数据,但这并不是唯一的考虑因素。将 GPU 与手头的特定 AI 任务相匹配至关重要。此外,还必须将总体成本纳入决策之中,以确保所选 GPU 能够为其预期用途提供最佳价值和效率。
成本和性能考虑
性能基准测试显示 H100 领先,但从财务角度来看这合理吗?毕竟,在大多数云提供商中,H100 通常比 A100 更贵。
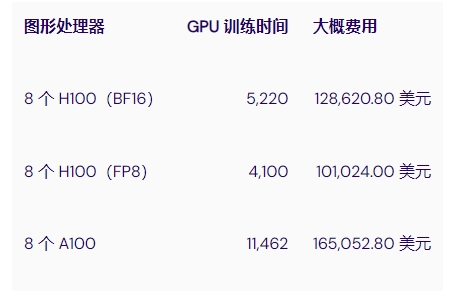
为了更好地了解 H100 是否值得增加成本,我们可以使用 MosaicML 的工作,该工作估算了在 134B 个 token 上训练 7B 参数 LLM 所需的时间
175B LLM 上的 FlashAttention2 培训
如果我们考虑捷智算平台对这些 GPU 的定价,我们可以看到在一组 H100 上训练这样的模型可以节省高达 39% 的成本,并且训练时间可以减少 64%。当然,这种比较主要与 FP8 精度的 LLM 训练有关,可能不适用于其他深度学习或 HPC 用例。
展望 GH200
2024 年,我们将看到 NVIDIA H200 的广泛可用性,它拥有更大的内存和更高的带宽(高达 4.8 TB/s),据说推理能力比 H100 提高了 1.6 倍到 1.9 倍。未来,我们将对这款产品和 L40(看起来更适合 ML 生命周期的推理部分)进行未来分析。敬请期待!
开始使用捷智算平台
进入捷智算平台官网,即可访问并按需租赁 H100、A100 和更多 GPU。或者,联系我们,我们可以帮助您设置满足您所有需求的私有 GPU 集群。











