
图形处理单元 (GPU) 加速器已成为一项关键技术。随着人工智能 (AI) 的进步和数据生成的指数级增长,高性能计算(HPC)和高级图形工作负载,对强大计算资源的需求从未如此强烈。凭借其并行处理能力,GPU 加速器已成为高效处理这些数据密集型任务的重要工具,从而实现更快的洞察和实时决策。
NVIDIA 是技术领域的领先企业,处于这场 GPU 革命的前沿。他们的 A100 和 H100 GPU 改变了游戏规则,旨在高效处理要求苛刻的计算任务。采用 Ampere 架构的 NVIDIA A100 为加速 AI、HPC 和图形工作负载树立了新标准。它提供前所未有的性能和灵活性,使其成为数据中心和研究机构的首选。
另一方面,NVIDIA H100作为该系列的最新产品,它将性能提升到了一个全新的水平。它旨在为 AI、HPC 和图形提供无与伦比的加速,使用户能够解决一些最具挑战性的计算问题。借助这些 GPU,NVIDIA 继续塑造技术的未来,突破数字计算的极限。本文比较了 NVIDIA A100 和 H100 GPU,重点介绍了它们的架构、性能基准、AI 功能和能效。
一、比较 A100 和 H100 架构
A100 和 H100 GPU 专为 AI 和 HPC 工作负载而设计,由不同的架构理念驱动。以下是它们之间的比较:
1、NVIDIA A100 的 Ampere 架构
NVIDIA A100 Tensor Core GPU 由革命性的 NVIDIA Ampere 架构,代表了 GPU 技术的重大进步,特别是对于高性能计算(HPC)、人工智能(AI)和数据分析工作负载而言。
该架构以之前的 Tesla V100 GPU 的功能为基础,增加了许多新功能并显著提高了性能。
A100 及其 Ampere 架构的主要特点包括:
第三代 Tensor Cores:
这些核心显著提高了 V100 的吞吐量,并为深度学习和 HPC 数据类型提供全面支持。它们提供新的 Sparsity 功能,可使吞吐量翻倍,提供 TensorFloat-32 运算以加速 FP32 数据处理,以及新的 Bfloat16 混合精度运算。
先进的制造工艺:
为 A100 提供动力的基于 Ampere 架构的 GA100 GPU 采用台积电 7nm N7 制造工艺制造。它包含 542 亿个晶体管,可提供更高的性能和功能。
增强内存和缓存:
A100 具有大型 L1 缓存和共享内存单元,与 V100 相比,每个流式多处理器 (SM) 的总容量是 V100 的 1.5 倍。它还包括 40 GB 的高速 HBM2 内存和 40 MB 的二级缓存,比其前代产品大得多,可确保高计算吞吐量。
多实例 GPU (MIG):
此功能允许 A100 划分为最多七个单独的 GPU 实例,用于 CUDA 应用程序,从而为多个用户提供专用的 GPU 资源。这提高了 GPU 利用率,并在不同客户端(例如虚拟机、容器和进程)之间提供了服务质量和隔离。
第三代 NVIDIA NVLink:
这种互连技术增强了多 GPU 的可扩展性、性能和可靠性。它显著增加了 GPU 之间的通信带宽,并改善了错误检测和恢复功能。

与 NVIDIA Magnum IO 和 Mellanox 解决方案的兼容性:
A100 与这些解决方案完全兼容,可最大限度地提高多 GPU 多节点加速系统的 I/O 性能并促进广泛的工作负载。
通过 SR-IOV 支持 PCIe Gen 4:
通过支持 PCIe Gen 4,A100 将 PCIe 3.0/3.1 带宽增加了一倍,这有利于与现代 CPU 和快速网络接口的连接。它还支持单根输入/输出虚拟化,允许为多个进程或虚拟机提供共享和虚拟化的 PCIe 连接。
异步复制与屏障特点:
A100 包含新的异步复制和屏障指令,可优化数据传输和同步并降低功耗。这些功能提高了数据移动和计算重叠的效率。
任务图加速:
A100 中的 CUDA 任务图使向 GPU 提交工作的模型更加高效,从而提高了应用程序的效率和性能。
增强型 HBM2 DRAM 子系统:
A100 继续提升 HBM2 内存技术的性能和容量,这对于不断增长的 HPC、AI 和分析数据集至关重要。
NVIDIA A100 采用 Ampere 架构,代表一种先进而强大的 GPU 解决方案,旨在满足现代 AI、HPC 和数据分析应用程序的苛刻要求。
H100 比 A100 快多少?
H100 GPU 最高可达快九倍用于 AI 训练,推理速度比 A100 快 30 倍。在运行 FlashAttention-2 训练时,NVIDIA H100 80GB SXM5 比 NVIDIA A100 80GB SXM4 快两倍。
2、NVIDIA H100 的 Hopper 架构
NVIDIA 的 H100 利用创新Hopper 架构专为 AI 和 HPC 工作负载而设计。该架构的特点是专注于 AI 应用的效率和高性能。Hopper 架构的主要特点包括:
第四代 Tensor Cores:
这些核心的性能比上一代快 6 倍,并针对对 AI 计算至关重要的矩阵运算进行了优化。
变压器引擎:
该专用引擎可加速人工智能的训练和推理,显著提高大型语言模型处理的速度。
HBM3 内存:
H100 是第一款配备 HBM3 内存的 GPU,带宽加倍,性能增强。
提高处理速度:
H100 具有强大的计算能力,IEEE FP64 和 FP32 速率比其前代产品快 3 倍。
DPX 说明:
这些新指令提高了动态规划算法的性能,这对于基因组学和机器人技术的应用至关重要。
多实例 GPU 技术:
这项第二代技术可以安全且高效地分区 GPU,满足不同的工作负载需求。
先进的互连技术:
H100 采用了第四代 NVIDIA NVLink 和 NVSwitch,确保在多 GPU 设置中实现卓越的连接性和带宽。异步执行和线程块集群:这些功能可优化数据处理效率,这对于复杂的计算任务至关重要。
分布式共享内存:
该功能促进了SM之间高效的数据交换,提高了整体数据处理速度。
H100 采用 Hopper 架构,标志着 GPU 技术的重大进步。它体现了硬件的不断发展,旨在满足 AI 和 HPC 应用日益增长的需求。
二、性能基准
性能基准测试可以提供有关 NVIDIA A100 和 H100 等 GPU 加速器功能的宝贵见解。这些基准测试包括不同精度的每秒浮点运算次数 (FLOPS) 和特定于 AI 的指标,可以帮助我们了解每个 GPU 的优势所在,特别是在科学研究、AI 建模和图形渲染等实际应用中。
1、NVIDIA A100 性能基准
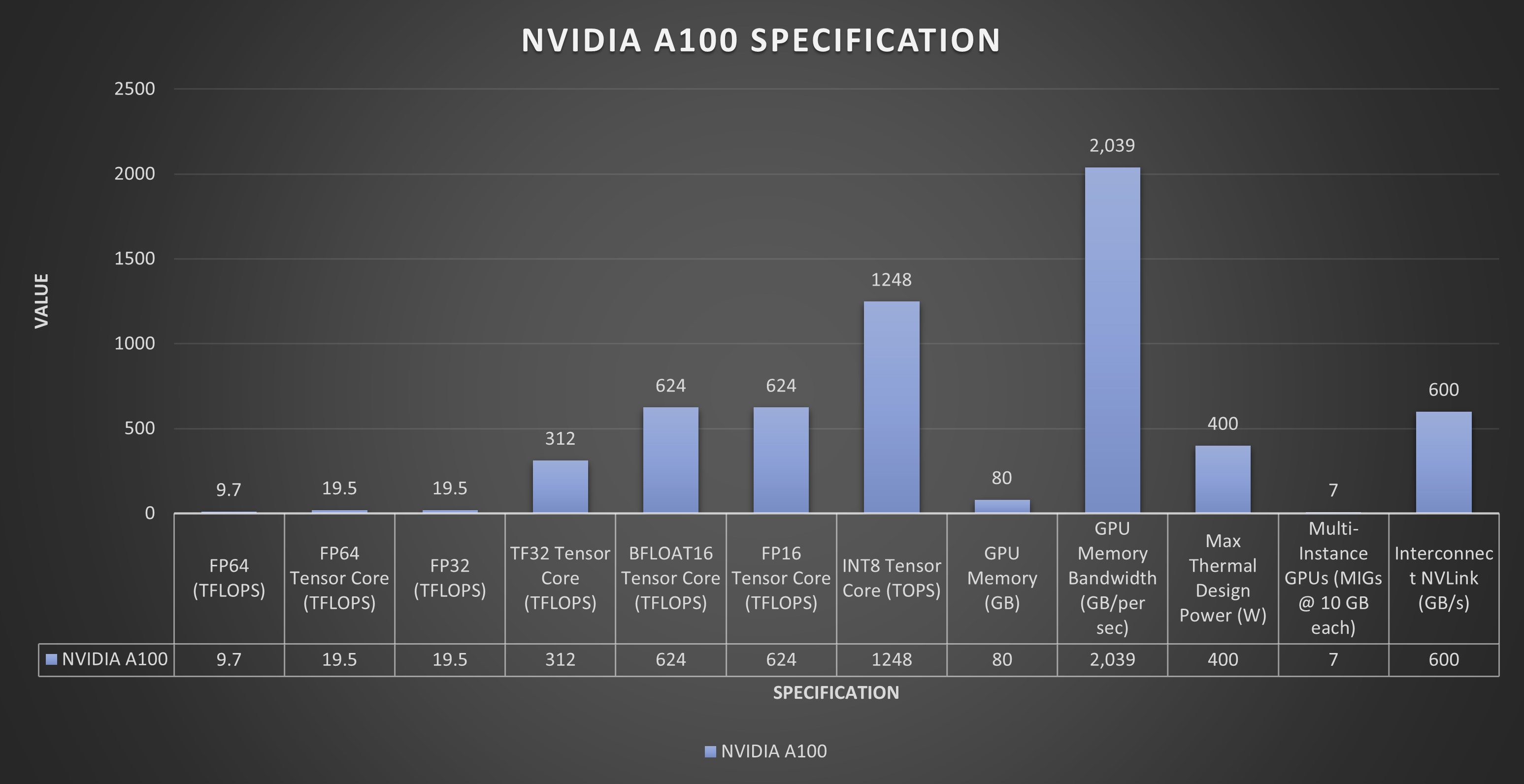
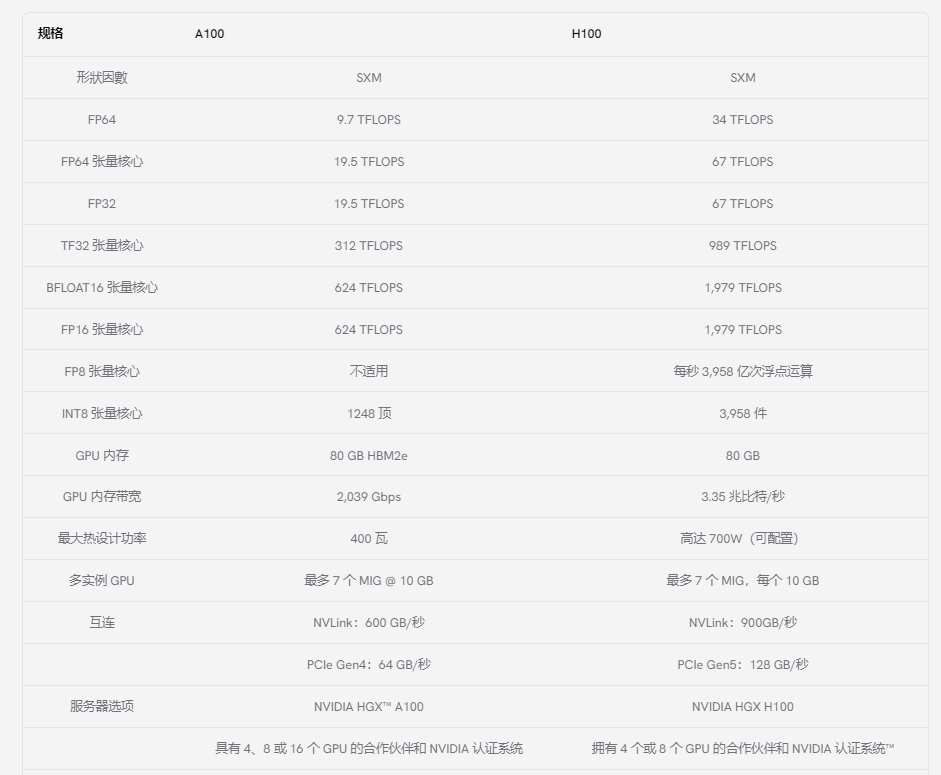
NVIDIA 的 A100 GPU 在各种基准测试中均表现出色。在浮点运算方面,A100 为双精度 (FP64) 提供高达 19.5 TFLOPS 的浮点运算能力,为单精度 (FP32) 提供高达 39.5 TFLOPS 的浮点运算能力。这种高计算吞吐量对于需要高精度的 HPC 工作负载(例如科学模拟和数据分析)至关重要。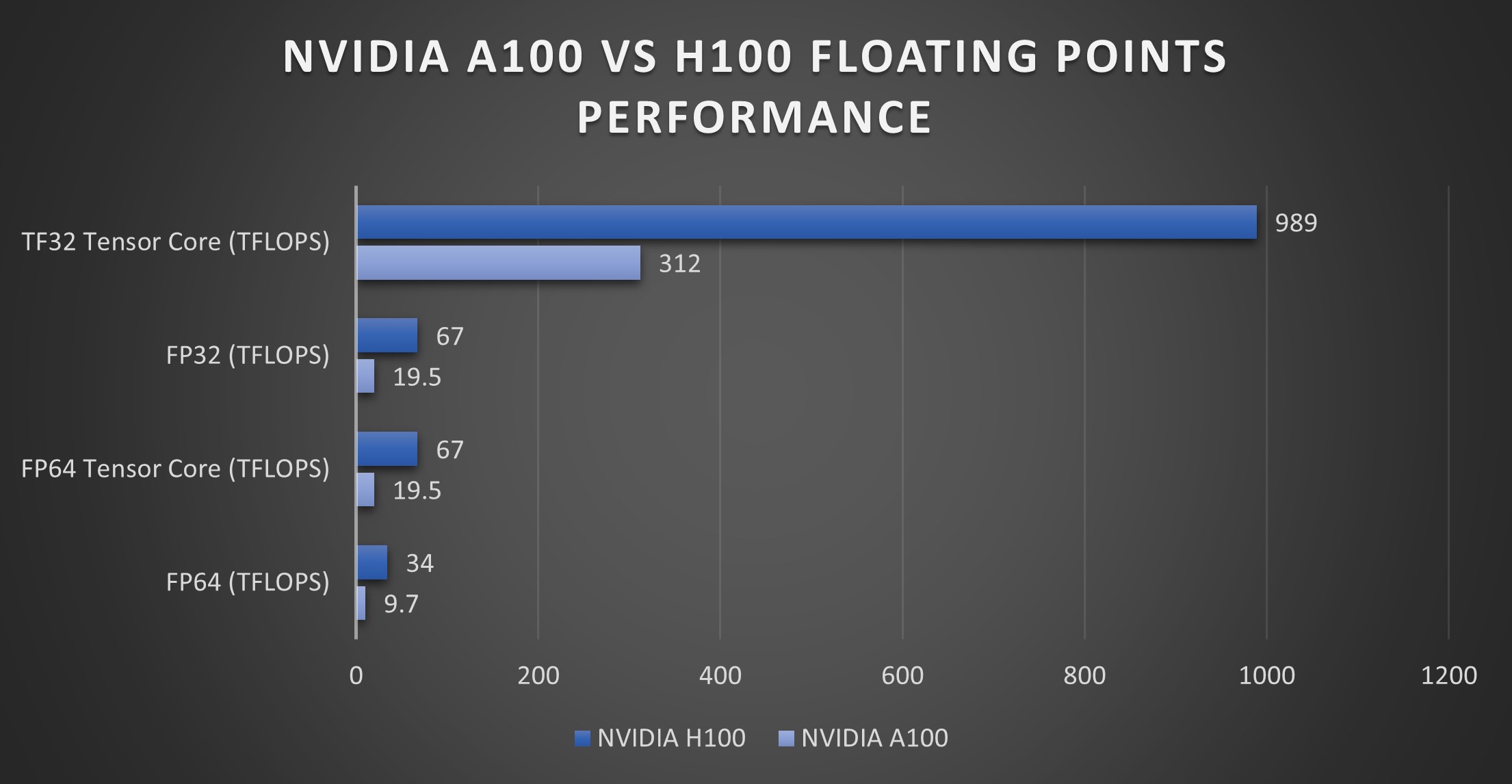
此外,A100 在张量运算方面表现出色,这对 AI 计算至关重要。张量核心可为 FP16 精度提供高达 312 TFLOPS 的性能,为张量浮点 32 (TF32) 运算提供高达 156 TFLOPS 的性能。这使得 A100 成为 AI 建模和深度学习任务的强大工具,这些任务通常需要大规模矩阵运算,并受益于张量核心提供的加速。
2、NVIDIA H100 性能基准
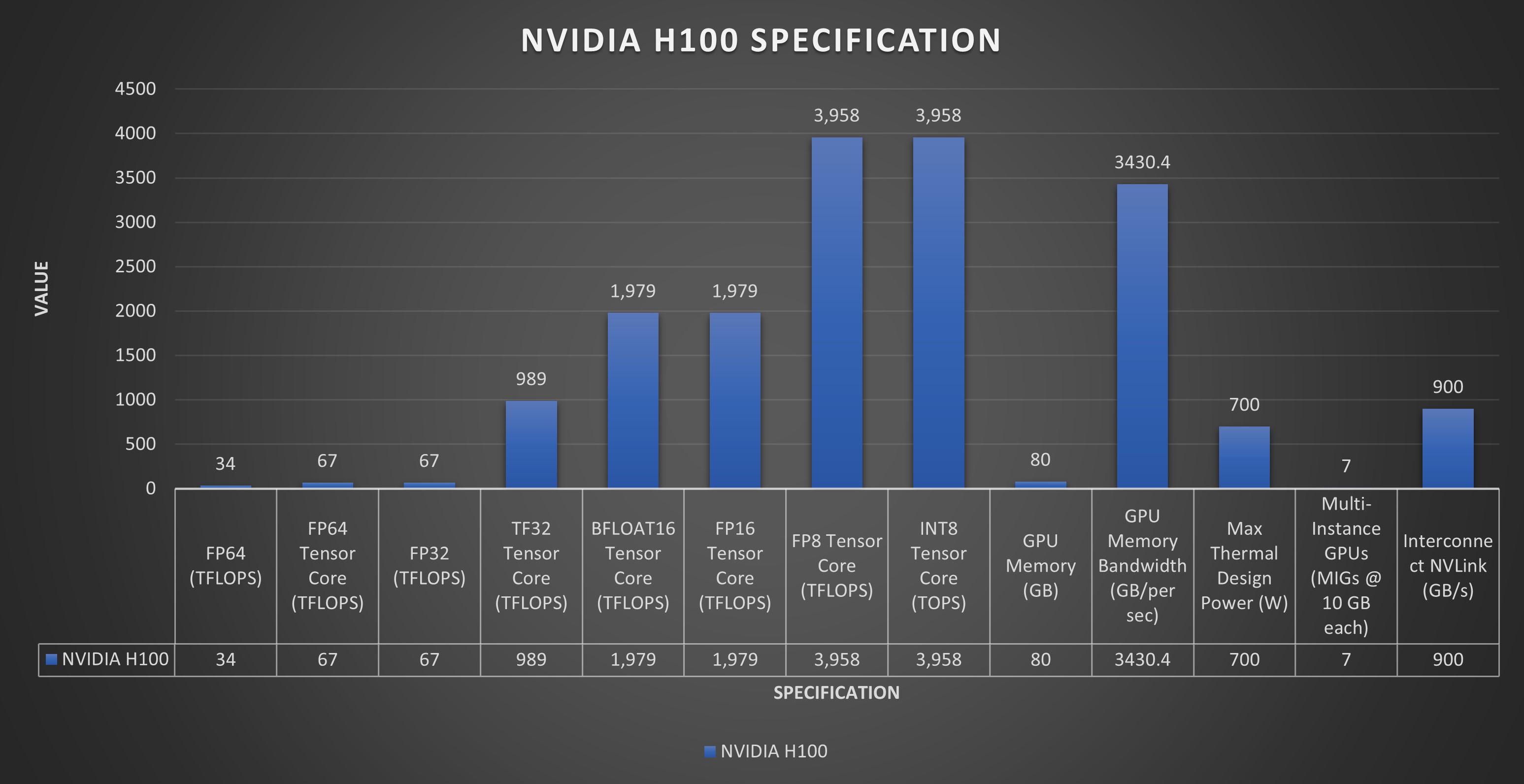
NVIDIA H100 GPU 在各种基准测试中均展现出卓越的性能。在浮点运算方面,虽然这里没有提供双精度 (FP64) 和单精度 (FP32) 的具体 TFLOPS 值,但 H100 旨在显著提高计算吞吐量,这对于科学模拟和数据分析等 HPC 应用至关重要。
张量运算对于 AI 计算至关重要,而 H100 的第四代 Tensor Core 预计将比前几代产品实现大幅性能提升。这些进步使 H100 成为一款功能极其强大的 AI 建模和深度学习工具,得益于大规模矩阵运算和 AI 特定任务的效率和速度提升。
三、人工智能和机器学习能力
人工智能和机器学习功能是现代 GPU 的关键组成部分,NVIDIA 的 A100和 H100 提供独特的功能,以增强其在 AI 工作负载中的性能。
1、张量核心:
NVIDIA A100 GPU 采用 Ampere 架构,在 AI 和机器学习方面取得了重大进展。A100 集成了第三代 Tensor Core,性能比 NVIDIA 的 Volta 架构(上一代)高出 20 倍。这些 Tensor Core 支持各种混合精度计算,例如 Tensor Float (TF32),从而提高了 AI 模型训练和推理效率。
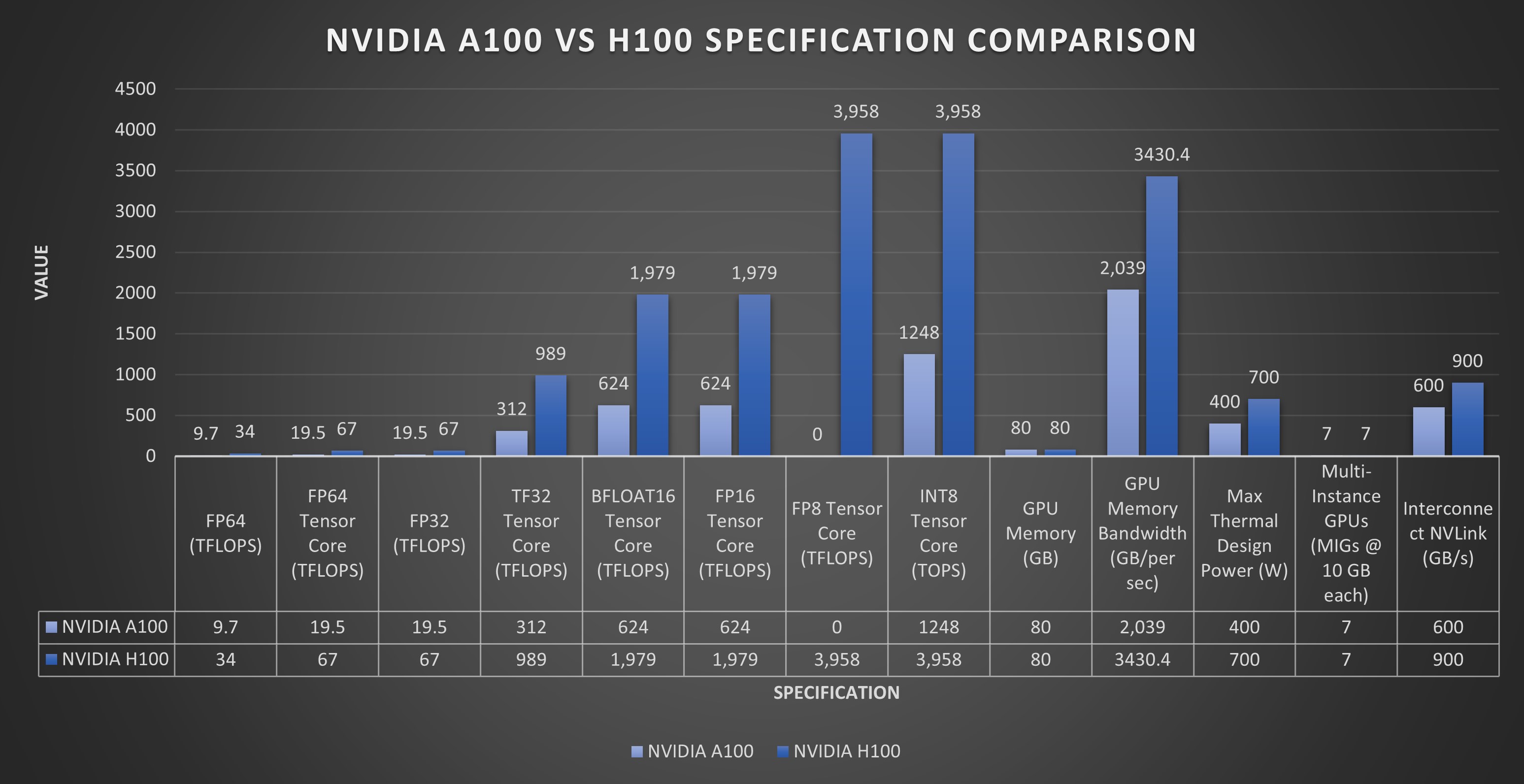
另一方面,NVIDIA H100 GPU 也代表了 AI 和 HPC 性能的重大飞跃。它具有新的第四代 Tensor Core,速度比 A100 中的速度快 6 倍。与 A100 相比,这些核心每个 SM 的矩阵乘法累加 (MMA) 计算速率提高了一倍,使用新的 FP8 数据类型时,增益甚至更大。此外,H100 的 Tensor Core 专为更广泛的 AI 和 HPC 任务而设计,并具有更高效的数据管理功能。
2、多实例 GPU (MIG) 技术:
A100 引入了 MIG 技术,允许将单个 A100 GPU 划分为多达七个独立实例。该技术优化了 GPU 资源的利用率,支持在单个 A100 GPU 上同时运行多个网络或应用程序。A100 40GB 版本最多可以为每个 MIG 实例分配 5GB,而 80GB 版本则将容量翻倍至每个实例 10GB。
然而,H100 采用了第二代 MIG 技术,每个 GPU 实例的计算能力比 A100 提高了约 3 倍,内存带宽提高了近 2 倍。这一进步进一步提高了 GPU 加速基础设施的利用率。
3、H100 的新功能:
H100 GPU 包含一个新的转换引擎,它使用 FP8 和 FP16 精度来增强 AI 训练和推理,特别是对于大型语言模型。与 A100 相比,该引擎可以提供高达 9 倍的 AI 训练速度和 30 倍的 AI 推理速度。H100 还引入了 DPX 指令,提供高达提升 7 倍的性能与 Ampere GPU 相比,动态规划算法更胜一筹。

总的来说,这些改进为 H100 提供了大约峰值计算吞吐量提高 6 倍。A100 的推出,标志着对苛刻的计算工作负载的重大进步。NVIDIA A100 和 H100 GPU 代表了 AI 和机器学习能力的重大进步,每一代都引入了创新功能,例如先进的 Tensor Cores 和 MIG 技术。H100 建立在 A100 的 Ampere 架构的基础上,进一步增强了 AI 处理能力和整体性能。
四、A100 或 H100 值得购买吗?
A100 或 H100 是否值得购买取决于用户的具体需求。这两款 GPU 都非常适合高性能计算 (HPC) 和人工智能 (AI) 工作负载。然而,H100 在 AI 训练和推理任务中速度明显更快。虽然 H100 更贵,但其卓越的速度可能值得特定用户花费。
五、电力效率和环境影响
NVIDIA 的 A100 和 H100 等 GPU 的热设计功率 (TDP) 等级提供了有关其功耗的宝贵见解,这对性能和环境影响都有影响。
1、GPU 热设计功耗:
A100 GPU 的 TDP 因型号而异。配备 40 GB HBM2 内存的标准 A100 的 TDP 为 250W。但是,A100 的 SXM 变体具有更高的 TDP,为 400W,而配备 80 GB 内存的 SXM 变体的 TDP 则增加到 700W。这表明 A100 需要强大的冷却解决方案,并且功耗相当大,具体功耗可能因具体型号和工作负载而异。
H100 PCIe 版本的 TDP 为 350W,接近其前身 A100 80GB PCIe 的 300W TDP。然而,H100 SXM5 支持高达 700W 的 TDP。尽管 TDP 如此之高,但 H100 GPU 比 A100 GPU 更节能,与 A100 80GB PCIe 和 SXM4 前身相比,FP8 FLOPS/W 分别增加了 4 倍和近 3 倍。这表明,虽然 H100 的功耗可能很高,但与 A100 相比,它的能效更高,尤其是在每瓦性能方面。
2、电源效率比较:
虽然 A100 GPU 的运行功率较低,为 400 瓦,但在某些工作负载下,其功率可低至 250 瓦,这表明与 H100 相比,其整体能效更高。另一方面,H100 的功耗更高,在某些情况下可高达 500 瓦。这一比较凸显出,虽然这两款 GPU 都很强大且功能丰富,但它们的功耗和效率存在很大差异,而 A100 整体上更节能。
虽然 NVIDIA A100 和 H100 GPU 都功能强大,但它们的 TDP 和能效特性不同。A100 的功耗因型号而异,但总体而言,它往往更节能。H100(尤其是其高端版本)的 TDP 更高,但每瓦性能更高,尤其是在 AI 和深度学习任务中。这些差异是必须考虑的,尤其是考虑到环境影响和对强大冷却解决方案的需求。
无论您选择 A100 经过验证的效率还是 H100 的先进功能,捷智算平台都会为您提供卓越计算性能所需的资源。











