
我需要什么才能运行最先进的文本到图像模型?游戏卡可以完成这项工作吗?还是我应该买一个高级的 A100?如果我只有 CPU 怎么办?
为了阐明这些问题,我们提出了不同 GPU 和 CPU 上Stable Diffusion的推理基准。以下是我们的发现:
许多消费级 GPU 可以很好地完成这项工作,因为Stable Diffusion只需要大约 5 秒和 5 GB 的 VRAM 即可运行。
在输出单张图像的速度方面,最强大的 Ampere GPU(A100)仅比 3080 快 33%(或 1.85 秒)。
通过将批量大小推至最大值,A100 可以提供 2.5 倍的推理吞吐量(与 3080 相比)。
我们的基准测试使用文本提示作为输入并输出分辨率为 的图像。我们使用Huggingface 扩散器库中的模型实现,并从速度、内存消耗、吞吐量和输出图像质量方面分析推理性能。我们研究了硬件(GPU 模型、GPU 与 CPU)和软件(单精度与半精度、pytorch 与 onnxruntime)的不同选择如何影响推理性能。
作为参考,我们将提供以下 GPU 设备的基准测试结果:A100 80GB PCIe、RTX3090、RTXA5500、RTXA6000、RTX3080、RTX8000。
最后但并非最不重要的一点是,我们很高兴看到社区进展如此迅速。例如,“切片注意力”技巧可以进一步将 VRAM 成本降低到“低至 3.2 GB”,但推理速度会降低约 10%。我们也期待在不久的将来,一旦ONNX 运行时变得更加稳定,就可以使用 CUDA 设备对其进行测试。
速度
下图展示了使用不同的硬件和精度生成单幅图像的推理速度,使用(任意)文本提示:“一张宇航员在火星上骑马的照片”。
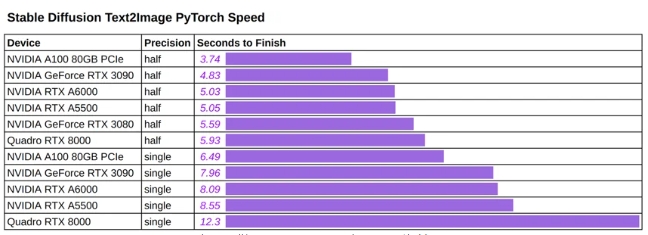
Stable Diffusion Text2Image 速度(以秒为单位)
我们发现:
在我们测试的 Ampere GPU 上,生成单个输出图像的时间范围3.74为5.59几秒,包括消费者 3080 卡到旗舰 A100 80GB 卡。
半精度可40%将安培 GPU 的时间减少约,将52%上一代RTX8000GPU 的时间减少约。
我们认为,由于使用了 ,Ampere GPU 的加速比半精度的“较小” TF32。对于不熟悉 的读者,它是一种格式,已被用作主要深度学习框架(如 PyTorch 和 TensorFlow)上 Ampere GPU 的默认单精度数据类型。由于它是一种真正的格式,因此可以预期半精度的加速比会更大。
我们在 CPU 设备上运行相同的推理作业,以便了解在 GPU 设备上观察到的性能。
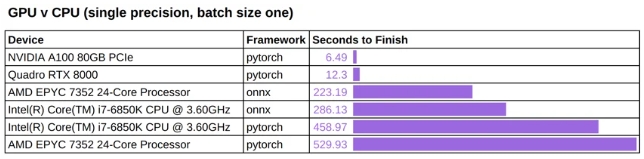
Stable Diffusion Text2Image GPU 与 CPU
我们注意到:
GPU 的速度明显更快——根据精度,速度可提高一到两个数量级。
onnxruntime可以将 CPU 推理时间减少约40%到50%,具体取决于 CPU 的类型。
顺便提一下,ONNX 运行时目前没有针对 Hugging Face 扩散器的稳定CUDA 后端支持,我们在初步测试中也没有观察到有意义的加速。我们期待在 ONNX 运行时针对Stable Diffusion进行进一步优化后进行更全面的基准测试。
内存
我们还测量了运行Stable Diffusion推理的内存消耗。
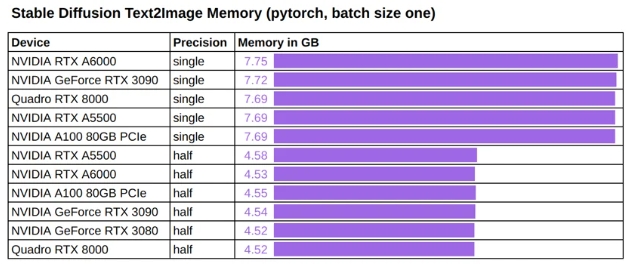
Stable Diffusion Text2Image 内存 (GB)
经观察,所有经过测试的 GPU 的内存使用情况都是一致的:
7.7 GB运行批量大小为 1 的单精度推理大约需要GPU 内存。
4.5 GB运行批量大小为 1 的半精度推理大约需要GPU 内存。
吞吐量
到目前为止,我们已经测量了单个输入的处理速度,这对于不能容忍哪怕是最小延迟的在线应用程序来说至关重要。但是,一些(离线)应用程序可能会关注“吞吐量”,它衡量在固定时间内处理的数据总量。
我们的吞吐量基准测试将每个 GPU 的批处理大小推至最大值,并测量它们每分钟可以处理的图像数量。最大化批处理大小的原因是让张量核心保持繁忙,以便计算可以主导工作负载,避免任何非计算瓶颈并最大化吞吐量。
我们在 pytorch 中以半精度运行了一系列吞吐量实验,并使用了每个 GPU 可以使用的最大批量大小:
Stable Diffusion文本到图像吞吐量(图像/分钟)
我们注意到:
再次,A100 80GB 表现最佳,且具有最高的吞吐量。
A100 80GB 与其他卡在吞吐量方面的差距可以通过此卡上可使用的最大批量大小较大来解释。
作为一个具体的例子,下图显示了当我们将批处理大小从 1 更改为 28(不会导致内存不足错误的最大值)时,A100 80GB 的吞吐量如何增加。同样有趣的是,当批处理大小达到某个值时,吞吐量的增长并不是线性的,而是趋于平稳,此时 GPU 上的张量核心已饱和,GPU 内存中的任何新数据都必须排队才能获得自己的计算资源。
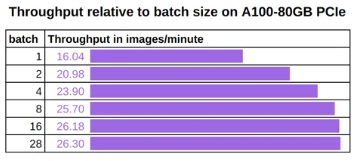
Stable Diffusion Text2Image 批次大小与吞吐量(图像/分钟)
自动播报
Hugging Face 团队对其扩散器代码进行的更新声称,删除自动投射可将 pytorch 的半精度推理速度提高约 25%。
使用自动播报:
with autocast("cuda"):
image = pipe(prompt).images[0]
未使用自动施放:
image = pipe(prompt).images[0]
我们在 NVIDIA RTX A6000 上重现了该实验,并能够验证速度和内存使用方面的性能提升。我们预计其他支持半精度的设备也会有类似的改进。

Stable Diffusion-text2image-pytorch-半精度速度
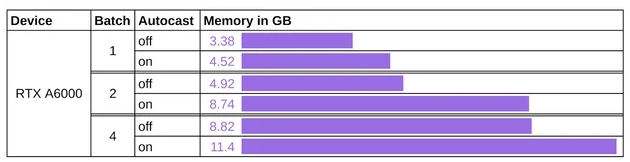
Stable Diffusion-text2image-pytorch-半精度内存
综上所述,请勿将 autocast 与 FP16 结合使用。
精确
我们很好奇半精度是否会降低输出图像的质量。为了测试这一点,我们修复了文本提示以及“潜在”输入,并将它们输入到单精度模型和半精度模型中。我们以增加的步数运行了 100 次推理。每次运行时,都会保存两个模型的输出及其差异图。

100 步中的单精度与半精度
我们的观察是,单精度输出和半精度输出之间确实存在明显差异,尤其是在早期步骤中。差异通常会随着步骤数量的增加而减小,但可能不会消失。
有趣的是,这种差异可能并不意味着半精度输出中存在伪影。例如,在步骤 70 中,下图显示半精度没有在单精度输出中产生伪影(额外的前腿):

单精度 v 半精度,步骤 70
重复实验
您可以使用捷智算平台自带的存储库来重现本文中呈现的结果。
设置
在运行基准测试之前,请确保您已完成存储库安装步骤。
然后您需要设置 huggingface 访问令牌:
1、在 Hugging Face 上创建用户账户并生成访问令牌。
2、将您的 huggingface 访问令牌设置为ACCESS_TOKEN环境变量:
export ACCESS_TOKEN=<hf_...>
用法
启动benchmark.py脚本以将基准测试结果附加到现有的 benchmark.csv 结果文件:
python ./scripts/benchmark.py
启动benchmark_quality.py脚本来比较单精度和半精度模型的输出:
python ./scripts/benchmark_quality.py
备注
由于每次运行的文本提示以及“潜在”输入都是固定的,这相当于运行 100 步推理,并保存每一步的中间结果。











