
Stable Diffusion 是一种人工智能模型,可将简单的文本提示转换为令人惊叹的高分辨率图像,为艺术家、设计师和爱好者开辟了创意可能性。然而,就像所有我们讨论过的生成式人工智能模型,Stable Diffusion需要大量的计算资源。
捷智算平台可访问 NVIDIA A40 GPU,旨在加速 AI 工作负载。通过将Stable Diffusion与 A40 的高性能功能相结合,您可以生成复杂的艺术品、尝试各种风格,并在比仅使用 CPU 更短的时间内将您的艺术构想变为现实。
无论您是经验丰富的 AI 艺术家还是好奇的初学者,本指南都将引导您在捷智算平台上使用 NVIDIA A40 实现Stable Diffusion。我们将介绍从获取模型到启动第一个图像生成项目的所有内容。
选择您的型号
第一步是选择模型。在本指南中,我们将使用Stable AI 的Stable Diffusion模型。该模型及其文档位于 hugging face 上。
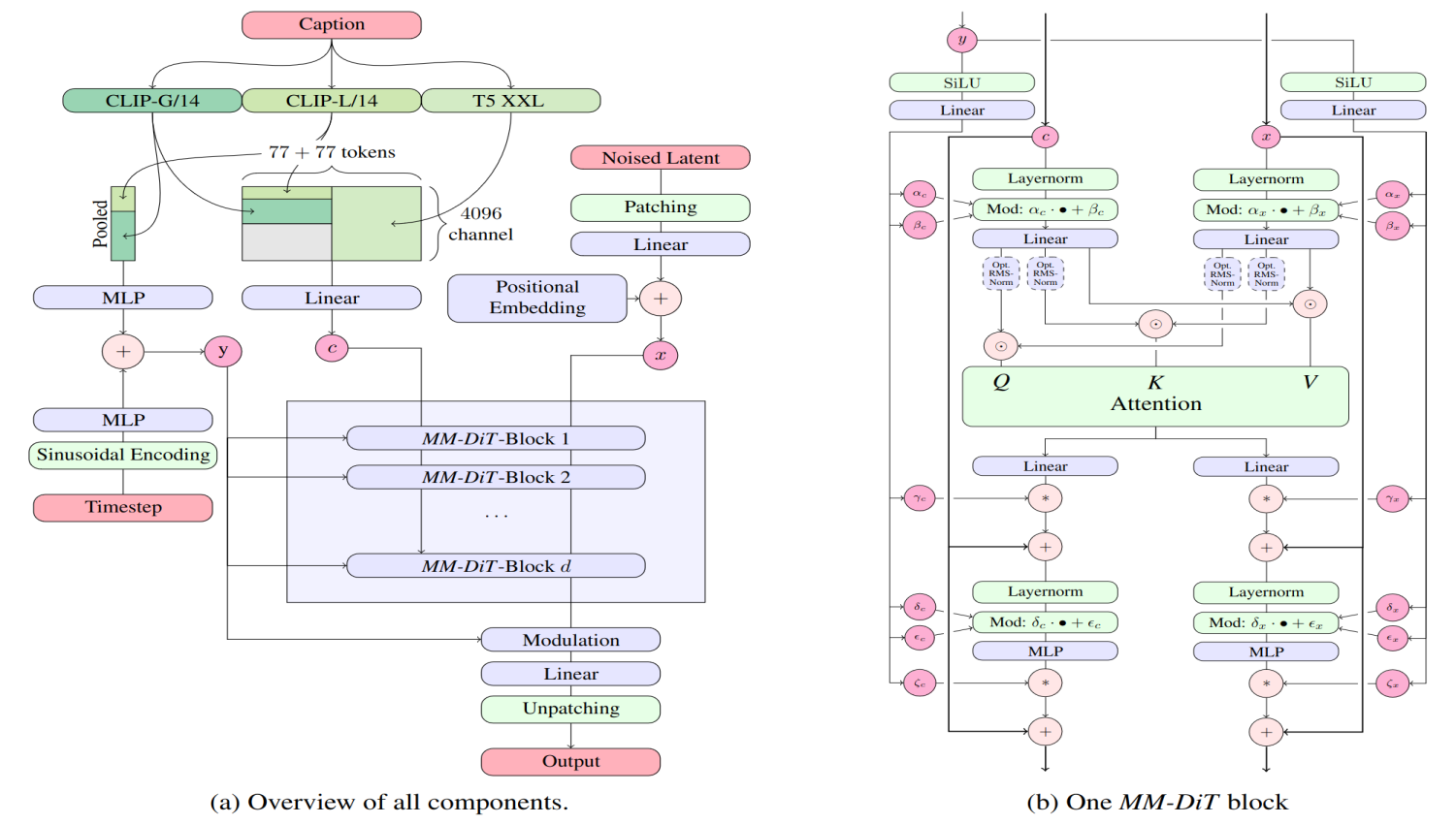 来源:Stability AI
来源:Stability AI
从 hugging face 获取模型时,您首先必须创建一个帐户。完成后,您必须生成一个访问令牌,您将使用该令牌将模型拉入您的 VM。为此,请单击您的个人资料图片并导航到“设置”。
单击“访问令牌”,然后单击“创建新令牌”。
选择此令牌的所有必要权限、您希望它访问的存储库、您希望它访问的组织等等。完成后,单击“创建令牌”。复制令牌并将其保存在安全的地方。
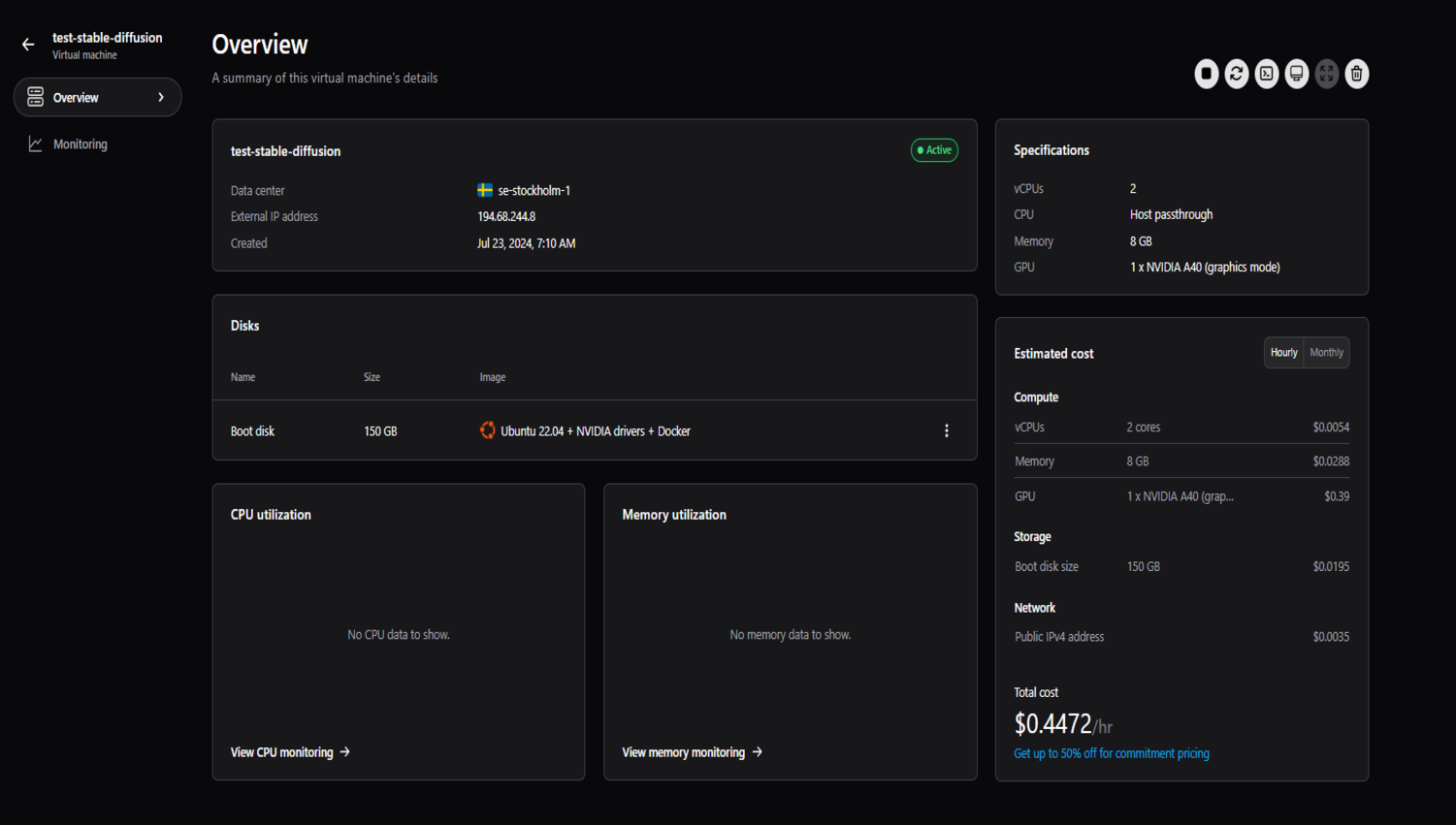
接下来,在捷智算平台上创建项目并创建虚拟机。我们将使用 NVIDIA A40 以及 2 个 vCPU、8GB 内存和 150GB 启动盘。
通过 SSH 进入您的虚拟机,然后运行更新和升级命令。
sudo apt update && sudo apt upgrade -y
然后安装 pip,我们将在安装其他 Python 库和框架时使用它,命令如下:
apt install python3-pip
接下来,我们将在机器上安装虚拟环境。即使您在虚拟机中工作,出于以下原因,最好这样做:
隔离:虚拟环境隔离了项目的 Python 依赖项,从而避免了可能需要同一库的不同版本的不同项目之间发生冲突。在没有虚拟环境的情况下为一个项目安装库可能会破坏依赖于不同版本的另一个项目。
可重复性:虚拟环境确保您的项目具有正确运行所需的精确依赖关系,从而更容易与他人共享您的项目或将其部署到生产中,因为您可以确信环境将是相同的。
整洁:虚拟环境使整个系统的 Python 安装保持整洁。您不会因项目特定的依赖项而弄乱虚拟机的全局库,从而更轻松地在虚拟机上管理 Python。
即使您在提供一定隔离的云虚拟机中工作,虚拟环境也能对特定于您的项目的依赖项提供更细粒度的控制。
我们将使用venv在本指南中,但您可以使用不同的工具来管理您的虚拟环境,例如conda。由于我们使用的是 Ubuntu 系统,因此我们必须使用以下命令安装 python3-venv 包。
apt install python3.10-venv
现在,我们将为项目创建一个文件夹并导航到其中。
mkdir stable_diffusion && cd stable_diffusion
我们将使用之前安装的 venv 在此文件夹中创建虚拟环境。
python3 -m venv venv
您应该在此目录中有一个 venv 文件夹,如上图所示。接下来,使用此命令激活虚拟环境。
source venv/bin/activate
激活虚拟环境后,我们可以安装所需的库和依赖项。
pip install torch torchvision torchaudio diffusers huggingface_hub matplotlib accelerate transformers sentencepiece protobuf
这需要一点时间才能运行。完成后,您就可以在捷智算平台上使用稳定扩散了。
接下来,我们将创建一个脚本来在虚拟机上测试该模型。
首先,我们将创建一个文件夹来保存我们想要用这个模型生成的图像。
mkdir generated_images
然后,我们开始编写代码。
导入您需要的所有模块。
import os
import torch
from diffusers import DiffusionPipeline
from huggingface_hub import HfFolder, login
from PIL import Image
接下来,我们必须验证我们的 Hugging Face ID 来提取模型。
# Set your Hugging Face token
token = "your_hugging_face_token"
os.environ["HF_AUTH_TOKEN"] = token
HfFolder.save_token(token)
# Login with your token
login(token=token)
该令牌将是您之前创建的 Hugging Face 令牌。
警告:将 Hugging Face 令牌(或任何密钥)留在代码库中存在安全风险。访问您代码的人可能会窃取令牌并用它来生成图片,甚至访问您的 Hugging Face 帐户。
始终使用环境变量安全地存储令牌、密码和其他机密,以防止这种情况发生。这样可以将它们与代码分开,并使它们更难被意外泄露。
接下来,我们使用Diffusion Pipeline加载模型。
# Load the model using DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
这几行代码执行与加载和配置用于图像生成的扩散模型相关的两个关键操作:
加载模型:
DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers"):此行使用来自扩散器库的 DiffusionPipeline 类的 from_pretrained 方法。它从 Hugging Face Hub 下载预先训练的扩散模型。此处加载的具体模型是“stabilityai/stable-diffusion-3-medium-diffusers”,它是 Stable Diffusion 3 模型的中型版本。
将模型移至 GPU:
pipe.to("cuda"):此行将加载的模型管道(管道)移动到启用 CUDA 的设备,如果可用,则为图形处理单元 (GPU),在我们的例子中,它是。如上所述,扩散模型的计算成本很高,与在 CPU 上运行相比,GPU 可以显著加速图像生成过程。
接下来,我们使用加载的扩散模型(管道)根据提供的文本提示和其他参数生成图像。
# Generate an image
result = pipe(
"A smiling cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
)
让我们分解一下每个元素:
result = pipe(...):此行调用 pipe 对象,该对象代表已加载的扩散管道。它要求模型根据括号内提供的参数生成图像。
“一只猫举着一块写着“你好世界”的牌子”:这个文本提示描述了所需的图像。模型将使用此信息来指导图像生成过程。
negative_prompt="":这是一个可选参数,用于指定负面提示。负面提示允许您告诉模型您不希望在图像中出现什么。在这里,我们使用一个空字符串,表示没有特定的负面提示。
num_inference_steps=28:此参数控制图像生成过程中使用的推理步骤数。每个步骤都会根据模型对提示的理解来细化图像。值越高,图像质量就越高,但生成图像的时间也越长。
guide_scale=7.0:此参数控制文本提示对生成图像的影响。较高的值会增加模型对提示的遵守程度,而较低的值则允许更多的创作自由。
执行此代码后,result 变量将包含有关生成的图像的信息,包括实际图像数据本身。接下来,我们检索生成的图像并将其保存到特定位置。
# Get the generated image
image = result.images[0]
# Save the image
image_path = "generated_images/generated_image.png"
image.save(image_path)
具体如下:
1、检索图像:
result.images 0:如前所述,result 变量保存有关生成图像的信息。在这里,我们访问 result 中的 images 属性。此属性可能包含生成的图像列表(可能用于变体或多次生成运行)。我们使用0来访问列表中的第一个图像(假设只有一个生成的图像)。
2、保存图像
image_path = "generated_images/generated_image.png":此行定义图像的保存路径。它将图像保存为文件名“generated_image.png”。
image.save(image_path):此行使用图像对象的 save 方法(我们从 result.images 0中检索到)。该方法将 image_path 作为参数,指定保存图像的目标位置。
要运行代码,请使用 python3 命令。假设文件保存为 app.py,请使用以下命令。
python3 app.py
如果您第一次运行代码,它将从 Hugging Face 下载模型并生成图像。
图像将保存在您的 generated_images 文件夹中。要查看它,您只需使用安全复制 (SCP) 将图像复制到本地计算机即可。为此,请导航到本地计算机上的命令行并运行此命令。
scp root@external_ip:~/stable_diffusion/generated_images/generated_image.png the/destination/path
注意:将 External_IP 替换为虚拟机的实际 IP 地址。如果您已经为虚拟机设置了命名主机,就像我们一样,你可以改用这个命令:
scp sdserver:~/stable_diffusion/generated_images/generated_image.png the/destination/path
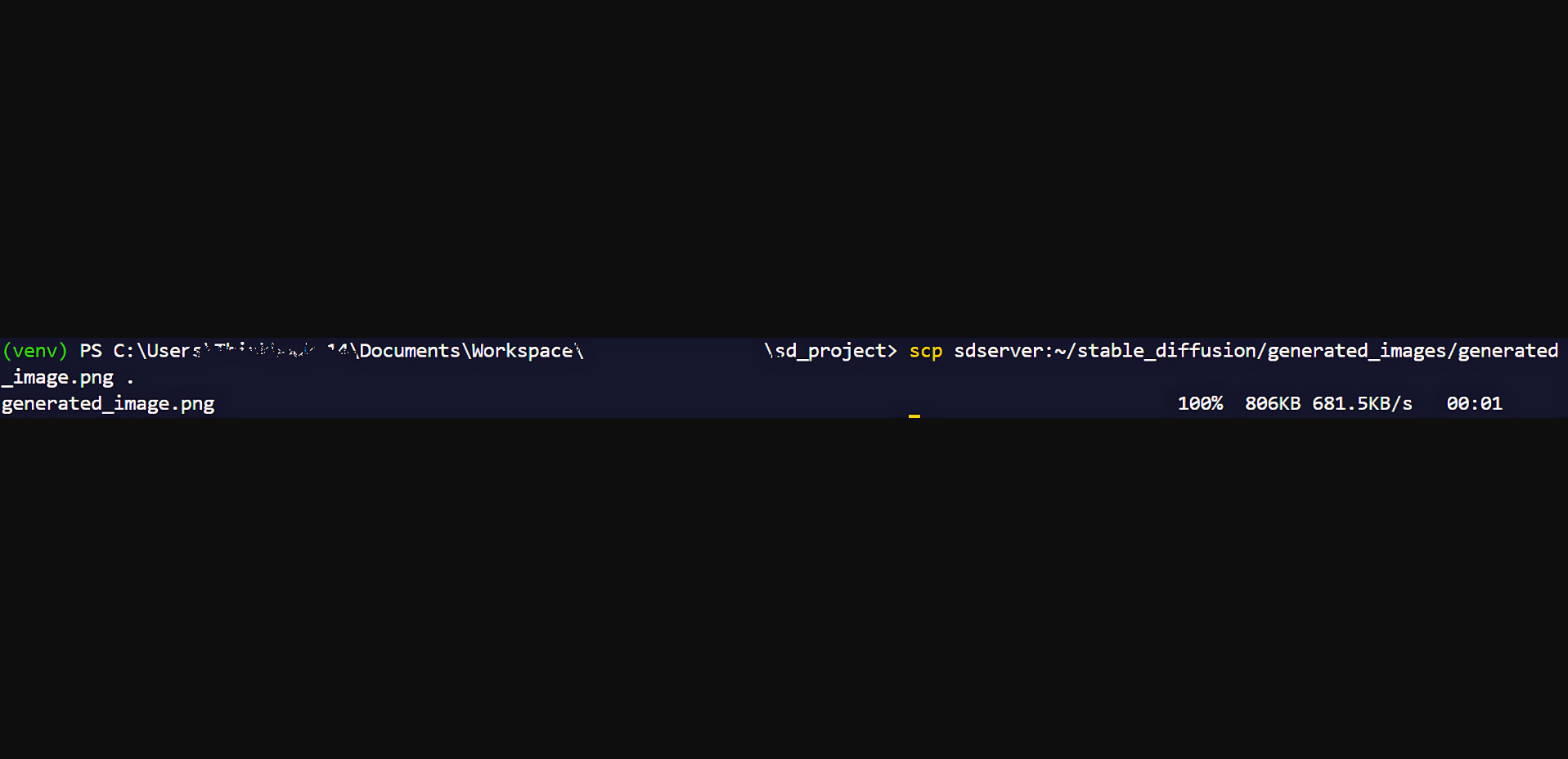
图像将被复制到您的计算机中。

当在捷智算平台上使用 A40 GPU 执行稳定扩散任务时,执行速度与本地机器明显不同。
import os
import torch
from diffusers import DiffusionPipeline
from huggingface_hub import HfFolder, login
from PIL import Image
import time # Import the time module
# Set your Hugging Face token
token = "your_hugging_face_model"
os.environ["HF_AUTH_TOKEN"] = token
HfFolder.save_token(token)
# Login with your token
login(token=token)
# Start time measurement
start_time = time.time()
# Load the model using DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-3-medium-diffusers", torch_dtype=torch.float16)
pipe = pipe.to("cuda")
# Generate an image
result = pipe(
"A cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=28,
guidance_scale=7.0,
)
# Get the generated image
image = result.images[0]
# Save the image
image_path = "generated_images/generated_image.png"
image.save(image_path)
# End time measurement
end_time = time.time()
# Calculate and display execution time
execution_time = end_time - start_time
print(f"Script execution time: {execution_time:.2f} seconds")
下载模型后首次运行时该脚本在 CUDO Compute 上的平均执行时间约为 67 秒。
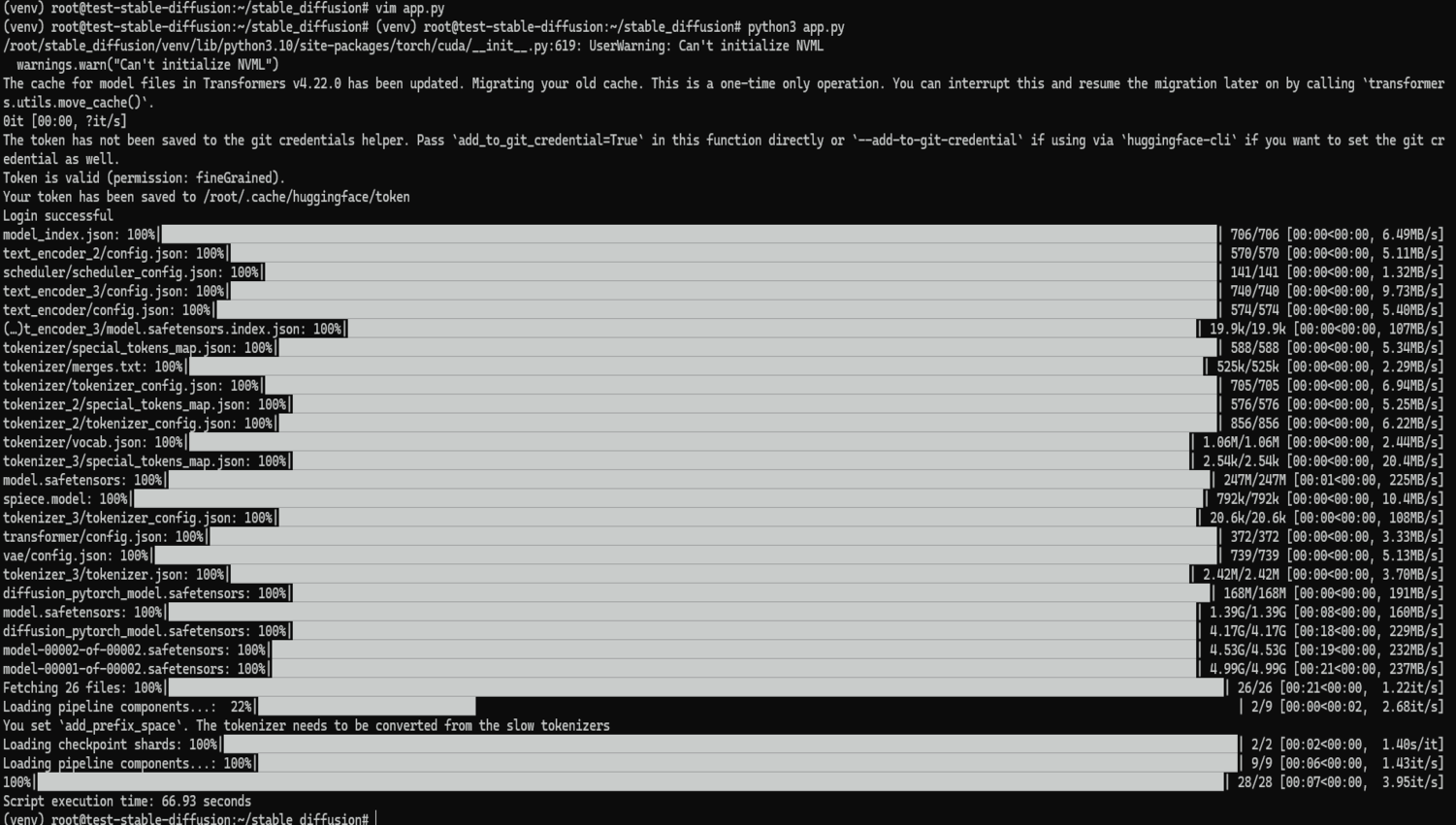

在后续运行中,当模型已缓存时,执行时间平均下降到 41 秒左右。在一台台式计算机上运行相同的脚本可能需要数小时。
总结
在本指南中,您已成功学习了如何使用捷智算平台上的 NVIDIA A40 GPU 和Stable Diffusion模型根据文本提示生成图像。您已学习了如何:
使用 GPU 在捷智算平台上设置虚拟机。
创建和管理 Python 虚拟环境以使您的项目保持井然有序。
安装使用 Stable Diffusion 所需的库和工具。
通过 Hugging Face 进行身份验证即可下载模型。
编写一个 Python 脚本,根据文本提示生成图像。
将生成的图像传输到本地机器以供查看和共享。
您现在可以尝试不同的提示和参数,甚至可以在捷智算平台的基础设施上探索其他 AI 模型。无论您是艺术家、设计师还是 AI 爱好者,从文本生成图像的能力都是一个强大的工具,可以增强您的工作流程并激发新的想法。











